Ein Entwickler muss schnell eine Datenbankverbindung testen. Er fügt das Passwort direkt in die Konfigurationsdatei ein, pusht den Commit und macht weiter. Das Feature wird ausgeliefert. Das Passwort bleibt bestehen. Sechs Monate später wird das Repository geforkt, die CI/CD-Logs werden indexiert, und diese Anmeldedaten befinden sich an drei Stellen, die niemand überwacht.
So gelangen die meisten hartcodierten Secrets in die freie Wildbahn – durch Bequemlichkeit, die ihren Kontext überdauert. GitGuardian fand 28,65 Millionen neue hartcodierte Secrets, die 2025 zu öffentlichen GitHub-Repositories hinzugefügt wurden – ein Anstieg von 34 % im Jahresvergleich und ein Zuwachs von 152 % seit 2021.
Wichtige Erkenntnisse
- Hartcodierte Secrets sind Anmeldedaten, die direkt in Quellcode, Konfigurationen, Skripte oder Anwendungspakete eingebettet sind – statische Werte, die zur Entwicklungszeit geschrieben werden, anstatt zur Laufzeit aus einer sicheren Quelle injiziert zu werden.
- Private Repositories sind kein sicherer Ort für Secrets. Kompromittierte Entwicklerkonten, CI/CD-Integrationen, Forks und Backups erweitern die Angriffsfläche weit über das hinaus, was „privat" impliziert.
- KI-gestützte Entwicklung verschärft das Problem. Commits von KI-Codierungstools enthalten doppelt so häufig Secrets. Leaks von Anmeldedaten für KI-Dienste stiegen 2025 um 81 % im Jahresvergleich.
- Das Löschen der Zeile reicht nicht aus. Ein einmal committetes Secret verbleibt in der Git-Historie, in Forks, CI/CD-Logs und lokalen Klonen. Rotation oder Widerruf kommen zuerst. Das Entfernen ist der Bereinigungsschritt.
- Die Erkennung muss kontinuierlich und mehrstufig erfolgen. IDE-Plugins fangen Secrets vor dem Commit ab; CI/CD-Scanning erfasst, was durchrutscht; repositoryweite Scans decken historische Expositionen auf. Jede Ebene hat blinde Flecken. Keine davon funktioniert ohne einen definierten Verantwortlichen und einen Triage-Prozess für jeden Fund.
- Die Ursache ist Workflow-Reibung, nicht Nachlässigkeit. Entwickler hartcodieren Secrets, wenn es keine schnellere, genehmigte Alternative gibt. Prävention bedeutet, diese Reibung zu beseitigen – nicht nur Scanner hinzuzufügen.
- Jeder Anmeldedatentyp benötigt einen designierten Speicherort. Maschinen-Secrets gehören in einen Vault oder Secrets-Manager mit Laufzeit-Injection. Menschliche und geteilte Anmeldedaten gehören in einen Unternehmens-Passwort-Manager mit Zugriffskontrollen und Audit-Trails. Anmeldedaten ohne designierten Speicherort landen im Code.
Was sind hartcodierte Secrets?
Hartcodierte Secrets sind Passwörter, API-Schlüssel, Tokens, private Schlüssel oder andere Anmeldedaten, die direkt in Quellcode, Skripte, Konfigurationsdateien oder Anwendungspakete geschrieben werden. Es sind statische Werte, die zur Schreibzeit eingebettet werden, anstatt zur Laufzeit aus einer sicheren Quelle injiziert zu werden. MITRE klassifiziert diese Schwachstelle als CWE-798: Use of Hard-coded Credentials und bewertet die Exploit-Wahrscheinlichkeit als hoch.
Die OWASP-Community-Seite zur Verwendung von hartcodierten Passwörtern behandelt die passwortspezifische Variante, aber der volle Umfang hartcodierter Secrets geht weit über Passwörter hinaus.
| Secret-Typ | Beispiel | Warum es sensibel ist |
|---|---|---|
| Passwort | Datenbank- oder Admin-Konto-Passwort | Kann direkten Benutzer- oder Systemzugriff gewähren |
| API-Schlüssel | Cloud-, Zahlungs-, CRM- oder Messaging-API-Schlüssel | Kann Datenzugriff, Transaktionen oder Service-Missbrauch ermöglichen |
| Zugriffstoken | OAuth-Token, Git-Token, CI/CD-Token | Kann normale Anmeldeabläufe umgehen |
| SSH / privater Schlüssel | Deployment-Schlüssel oder Server-Schlüssel | Kann Server- oder Repository-Zugriff ermöglichen |
| Zertifikat / Schlüsselmaterial | TLS-privater Schlüssel oder Signaturschlüssel | Kann Identitätsvortäuschung oder Entschlüsselung ermöglichen |
| Verbindungszeichenkette | Datenbank-URL mit Benutzername und Passwort | Kombiniert oft Host, Konto und Passwort in einem Wert |
Wo tauchen hartcodierte Secrets normalerweise auf?
Hartcodierte Secrets erscheinen überall dort, wo Code geschrieben, gebaut, gespeichert oder bereitgestellt wird – eine weitaus größere Angriffsfläche, als den meisten Teams bewusst ist.
In der Codebasis und Versionskontrolle:
- Anwendungsquellcode und Inline-Kommentare
- Konfigurationsdateien (
.properties,.yaml,.json,.xml) - Versehentlich committete lokale Entwicklungsdateien (
.env,.env.local) - Infrastructure-as-Code-Vorlagen (Terraform, Ansible, CloudFormation)
In Build- und Deployment-Systemen:
- CI/CD-Pipeline-Definitionsdateien mit inline geschriebenen Anmeldedaten
- Build-Logs und Artefakte, die Umgebungswerte ausgeben
- Container-Images mit in Schichten eingebauten Secrets
In verteilten und eingebetteten Systemen:
- Mobile Apps und clientseitige JavaScript-Bundles
- Firmware, IoT-Geräte, Router und eingebettete Controller
In informeller Ablage:
- Dokumentation, interne Wikis und README-Dateien
- Support-Tickets, Jira-Vorgänge und Confluence-Seiten
- Slack-Exporte, E-Mail-Threads und geteilte Tabellenkalkulationen
Ein Hinweis zu .env-Dateien: Sie sind sicherer als das direkte Schreiben von Werten in den Code, aber nur wenn sie von der Versionskontrolle ausgeschlossen, lokal geschützt und niemals in Logs oder Build-Artefakte kopiert werden. Eine einmal committete .env-Datei ist ein hartcodiertes Secret.
Warum hartcodieren Entwickler Secrets?
Die Ursache ist fast nie Nachlässigkeit. Es ist Workflow-Reibung.
- Schnelles lokales Testen. Das Hartcodieren eines Wertes dauert zehn Sekunden. Das Einrichten einer Vault-Referenz dauert länger, besonders ohne eine Standardvorlage.
- Vermeidung von Konfigurationsabweichungen. Wenn Entwicklungs-, Staging- und Produktionsumgebungen inkonsistent verwaltet werden, hartcodieren Entwickler manchmal Werte, um sicherzustellen, dass die richtigen Anmeldedaten das richtige System erreichen.
- Kopieren aus Dokumentation oder Beispielen. Offizielle Dokumentationen und Stack-Overflow-Antworten zeigen häufig Anmeldedaten als Platzhalter. Diese Platzhalter werden durch echte Werte ersetzt und committet.
- KI-generierter Code. Coding-Assistenten können unsichere Muster aus Trainingsdaten reproduzieren oder Platzhalter-Anmeldedaten einfügen, die funktional aussehen. Das Risiko ist am höchsten, wenn generierter Code die normale Sicherheitsüberprüfung umgeht oder wenn ein Entwickler einen Platzhalter durch einen echten Wert ersetzt, ohne ihn an eine sichere Quelle zu verschieben.
- Kein standardisierter Secret-Management-Workflow. Wenn es keine genehmigte Methode gibt, Secrets lokal zu handhaben, erfinden Entwickler ihre eigene – und Bequemlichkeit gewinnt meist.
- Fehlende Pre-Commit-Prüfungen. Ohne automatisierte Gates kann ein hartcodiertes Secret mit einem einzigen Push vom Editor eines Entwicklers in ein geteiltes Repository gelangen.
- Unklare Eigentümerschaft von Dienstkonten und geteilten Anmeldedaten. Wenn niemand für Anmeldedaten verantwortlich ist, verwaltet sie auch niemand sicher.
Warum sind hartcodierte Secrets so riskant?
Die Zahlen machen den Trend schwer ignorierbar. GitGuardian verfolgte ~11 Millionen neue hartcodierte Secrets auf öffentlichem GitHub in 2021; bis 2025 erreichte diese Zahl 28.649.024 – ein Anstieg von 152 % in vier Jahren.
Neu erkannte hartcodierte Secrets auf öffentlichem GitHub, 2021–2025
Erkennung allein schließt die Lücke nicht: 64 % der 2022 als gültig bestätigten Secrets waren 2026 noch aktiv und ausnutzbar. Hartcodierte Secrets sind kein Altlastproblem, das schrittweise gelöst wird – die Angriffsfläche wächst schneller, als die Behebung mithalten kann.
| Risiko | Wie es passiert | Mögliche Auswirkung |
|---|---|---|
| Repository-Exposition | Code ist öffentlich, geforkt, zu weit geteilt oder über ein kompromittiertes Konto zugänglich | Angreifer erhalten nutzbare Anmeldedaten |
| Git-Historie-Persistenz | Secret verbleibt in früheren Commits nach einem „Fix"-Commit | Alte Anmeldedaten können weiterhin aus der Historie wiederhergestellt werden |
| CI/CD-Kompromittierung | Tokens in Pipeline-Dateien oder Logs gewähren Build- oder Deploy-Zugriff | Quellcode-Diebstahl, vergiftete Builds, Produktionszugriff |
| Cloud-Missbrauch | API-Schlüssel ermöglichen Zugriff auf Cloud-Ressourcen | Datendiebstahl, Krypto-Mining, Service-Unterbrechung, Kostenspitzen |
| Laterale Bewegung | Eine Anmeldedaten führt zu weiteren Systemen | Privilegien-Eskalation und breitere Kompromittierung |
| Compliance-Exposition | Anmeldedaten entsperren regulierte Daten oder auditrelevante Systeme | Bußgelder, Audit-Feststellungen, Meldepflichten bei Datenschutzverletzungen |
Private Repositories sind kein sicherer Ort für Secrets. Der Repository-Zugriff ist oft breiter als Administratoren annehmen. CI/CD-Tools, Backup-Systeme, Entwickler-Endpunkte, Drittanbieter-Integrationen und Forks erweitern alle die Angriffsfläche. Ein kompromittiertes Entwicklerkonto reicht aus, um jedes Secret in jedem privaten Repository zu extrahieren, das dieses Konto lesen kann.
Verizons 2025 DBIR stellte auch fest, dass Web-Anwendungsinfrastruktur 39 % der offengelegten Secrets in öffentlichen Git-Repositories ausmachte, und 66 % davon waren JWTs. Generische Secrets – die Kategorie, die am schwersten mit Pattern-Matching-Tools zu erkennen ist – machten laut GitGuardian 58 % aller geleakten Anmeldedaten im Jahr 2024 aus.
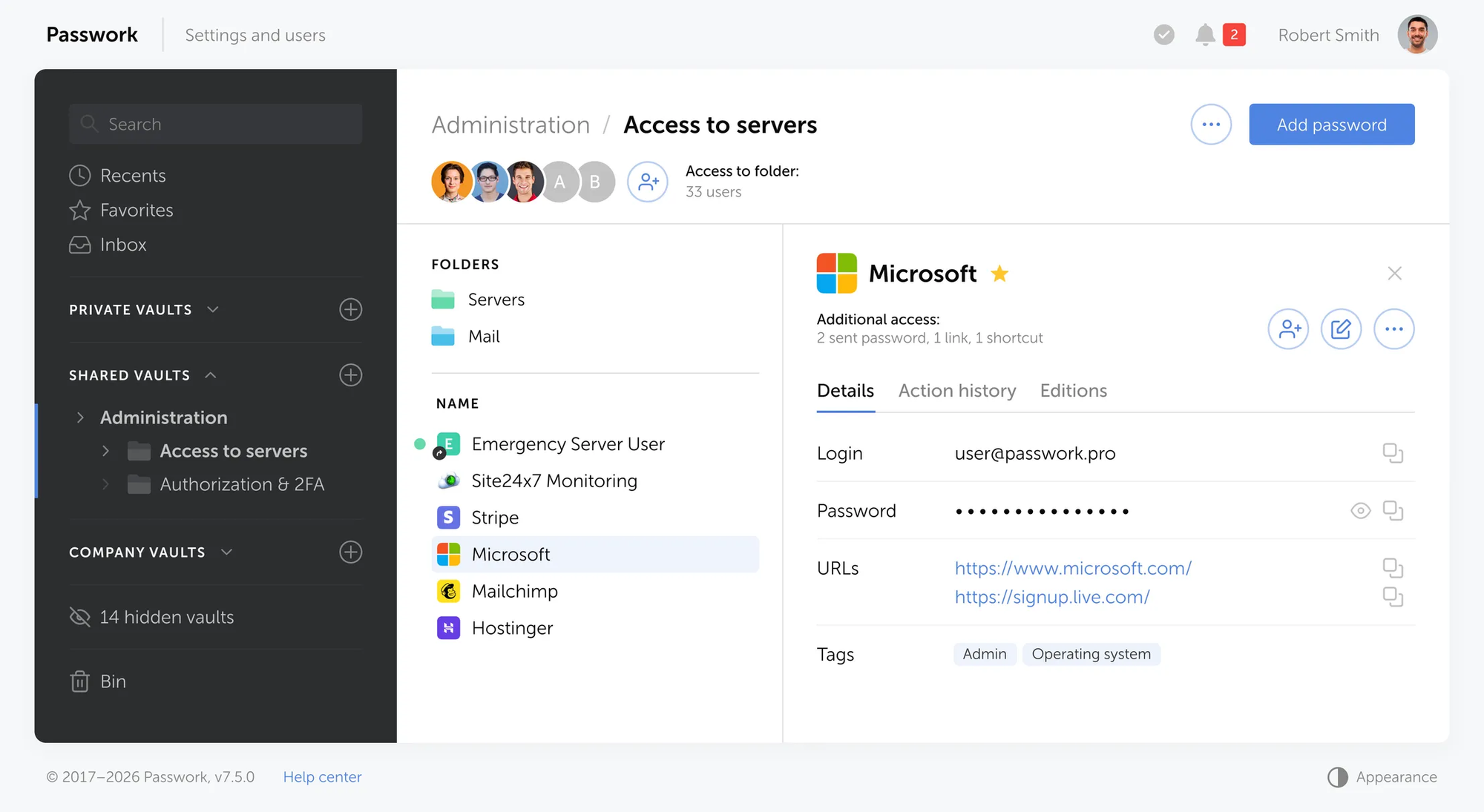
Passwork ist ein Unternehmens-Passwort- und Secrets-Manager: API-Schlüssel, Tokens, SSH-Schlüssel und Admin-Anmeldedaten – alles in verschlüsselten Tresoren mit rollenbasiertem Zugriff und Audit-Logs, nicht im Code oder in Chat-Threads. Passwork entdecken
Was sollten Sie tun, wenn ein hartcodiertes Secret gefunden wird?

Der Instinkt, die Zeile zu löschen und einen Fix-Commit zu pushen, ist verständlich. Er ist aber auch unzureichend. Sobald ein Secret committet ist, gehen Sie davon aus, dass es irgendwo kopiert, gecacht, geloggt oder indexiert wurde, wo Sie nicht heranreichen.
Incident-Response-Workflow
- Klassifizieren Sie das Secret. Bestimmen Sie, ob es sich um ein Passwort, einen API-Schlüssel, ein Token, einen privaten Schlüssel, ein Zertifikat oder eine Verbindungszeichenkette handelt.
- Identifizieren Sie den Eigentümer und den Umfang. Finden Sie heraus, welches System, welche Umgebung, welche Privilegienstufe und welches Konto das Secret kontrolliert.
- Widerrufen oder rotieren Sie sofort. Behandeln Sie den Wert ab dem Moment des Commits oder der Exposition als kompromittiert.
- Überprüfen Sie Zugriffsprotokolle. Suchen Sie nach verdächtigen Aktivitäten vor und nach dem Expositionsfenster.
- Entfernen Sie es aus der Codebasis. Ersetzen Sie den hartcodierten Wert durch eine Referenz zu einer sicheren Quelle.
- Bereinigen Sie die Repository-Historie bei Bedarf. Verwenden Sie genehmigte Tools wie
git filter-repooder BFG Repo-Cleaner und koordinieren Sie sich mit den Repository-Eigentümern – das Umschreiben der Historie betrifft alle Mitarbeiter. - Aktualisieren Sie abhängige Systeme. Bestätigen Sie, dass alle Anwendungen, Jobs und Integrationen den neuen Wert verwenden.
- Dokumentieren Sie den Vorfall. Erfassen Sie Ursache, Eigentümer, Behebungszeit und welche Kontrolle ein Wiederauftreten verhindern wird.
- Fügen Sie eine Präventionskontrolle hinzu. Pre-Commit-Hooks, CI/CD-Scanning, Richtlinien-Updates oder Zugriffsüberprüfung – mindestens eine konkrete Änderung vor Abschluss des Vorfalls.
Wie können Organisationen hartcodierte Secrets erkennen?
Einmaliges Scanning reicht nicht aus. Secrets gelangen kontinuierlich in Codebasen, und die Erkennung muss diesem Tempo entsprechen.
| Erkennungsebene | Was sie erfasst | Einschränkung |
|---|---|---|
| IDE-Plugins | Secrets bevor Code committet wird | Hängt von der Entwicklerakzeptanz ab; nicht zentral durchgesetzt |
| Pre-Commit-Hooks | Neue Secrets bevor sie in Git gelangen | Können umgangen werden, wenn nicht auf Repository-Ebene durchgesetzt |
| Pre-Push-Hooks | Secrets bevor Code ein Remote-Repository erreicht | Weiterhin lokal und vom Entwickler kontrolliert |
| CI/CD-Scanning | Secrets in Pull Requests und Builds | Kann nach Exposition gegenüber geteilten Systemen erkennen |
| Repositoryweite Scans | Historische Leaks über Branches und Commits | Erfordert Triage, Eigentümerzuordnung und Rotations-Workflow |
| Öffentliches Monitoring | Secrets, die in öffentlichen Repos oder Paste-Sites exponiert sind | Reaktiv, wenn nicht mit Prävention kombiniert |
| Gültigkeitsprüfungen | Ob ein erkanntes Secret noch funktioniert | Muss sorgfältig gehandhabt werden, um unsicheres Testen zu vermeiden |
Der Verizon 2025 DBIR stellte fest, dass die mediane Zeit zur Behebung entdeckter geleakter Secrets auf GitHub 94 Tage betrug. Diese Lücke besteht, weil Erkennung ohne Eigentümerschaft und Triage-SLAs zu Alarm-Müdigkeit führt, nicht zu Handlung. Jedes erkannte Secret benötigt einen benannten Eigentümer und einen definierten Reaktionspfad.
Wie können Teams hartcodierte Secrets verhindern?
Prävention ist ein mehrschichtiges Problem. Keine einzelne Kontrolle ist für sich allein ausreichend.
| Kontrolle | Was sie verhindert | Praktische Anleitung |
|---|---|---|
| Secrets-Manager oder Vault | Speicherung von Maschinen-Secrets im Code | Laufzeit-Secrets außerhalb der Codebasis speichern; zur Laufzeit injizieren |
| Umgebungsvariablen | Direktes Einbetten im Code | Nur mit strikten Umgebungskontrollen verwenden; niemals .env-Dateien committen |
| Pre-Commit- und CI-Scanning | Versehentliche Commits | Secrets vor Merge oder Deployment blockieren |
| Minimale Berechtigungen | Übermächtige geleakte Anmeldedaten | Tokens nur auf erforderliche Systeme und Aktionen beschränken |
| Kurzlebige Anmeldedaten | Lange Expositionsfenster | Wo möglich ablaufende Tokens und Workload-Identität bevorzugen |
| Rotationsrichtlinie | Anhaltendes Risiko durch alte Werte | Planmäßig und sofort nach jeder Exposition rotieren |
| Getrennte Umgebungen | Produktionskompromittierung durch Dev-Leaks | Unterschiedliche Anmeldedaten für Entwicklung, Test, Staging und Produktion verwenden |
| Entwicklerschulung | Wiederholte unsichere Abkürzungen | Genehmigte Muster erklären; einsatzbereite Vorlagen bereitstellen |
| Passwort-Governance | Über Code, Dokumente oder Chat geteilte Anmeldedaten | Geteilte menschliche und Admin-Passwörter in einem kontrollierten Passwort-Manager zentralisieren |
Die meisten Organisationen verwalten letztendlich beide Kategorien: Maschinen-Secrets für Anwendungen und Pipelines sowie menschliche Anmeldedaten für geteilte Admin-Konten, Team-Zugriff und operative Workflows. Sie in separaten, unverbundenen Systemen zu halten, schafft eigene Probleme – inkonsistente Zugriffsrichtlinien, doppelte Audit-Trails und Anmeldedaten, die durch die Lücke zwischen den Tools fallen. Passwork deckt beides in einer einzigen Plattform ab, unter einem Zugriffsmodell und einem Audit-Log.
Zwei Anmeldedaten-Kategorien, ein Ort für ihre Verwaltung
Die folgende Tabelle zeigt, wohin jeder Anmeldedatentyp gehört.
| Anmeldedaten-Kategorie | Besserer Speicherort | Grund |
|---|---|---|
| Passwörter menschlicher Benutzer | Unternehmens-Passwort-Manager | Unterstützt sicheres Teilen, Zugriffskontrolle, Überprüfung und Passwortrichtlinien |
| Geteilte Admin-Passwörter | Unternehmens-Passwort-Manager oder PAM-Workflow | Erfordert Nachvollziehbarkeit, Rotation und kontrollierten Team-Zugriff |
| Von Anwendungen verwendete API-Schlüssel | Secrets-Manager oder Cloud-Vault | Anwendungen benötigen Laufzeitabruf und automatisierte Rotation |
| CI/CD-Deployment-Tokens | CI/CD-Secret-Store oder Vault | Build-Systeme benötigen kontrollierte Injection und Auditierbarkeit |
| SSH-Schlüssel für Server | Schlüsselverwaltung / PAM / genehmigter sicherer Speicher | Erfordert Eigentümerschaft, Rotation und Zugriffs-Governance |
| Datenbank-Verbindungszeichenketten | Secrets-Manager oder Vault | Sollten zur Laufzeit injiziert werden, nicht in Code committet |
Das Ziel ist sicherzustellen, dass jede Anmeldedaten in einem System lebt, das für ihre tatsächliche Verwendung konzipiert ist. Für die meisten Teams bedeutet das eine Plattform, die beide Kategorien handhabt – nicht zwei separate Tools mit separaten Zugriffsmodellen und separaten Audit-Trails. Das ist die Lücke, die Passwork füllt.
Wie Passwork hartcodierte Secrets über den gesamten Stack eliminiert
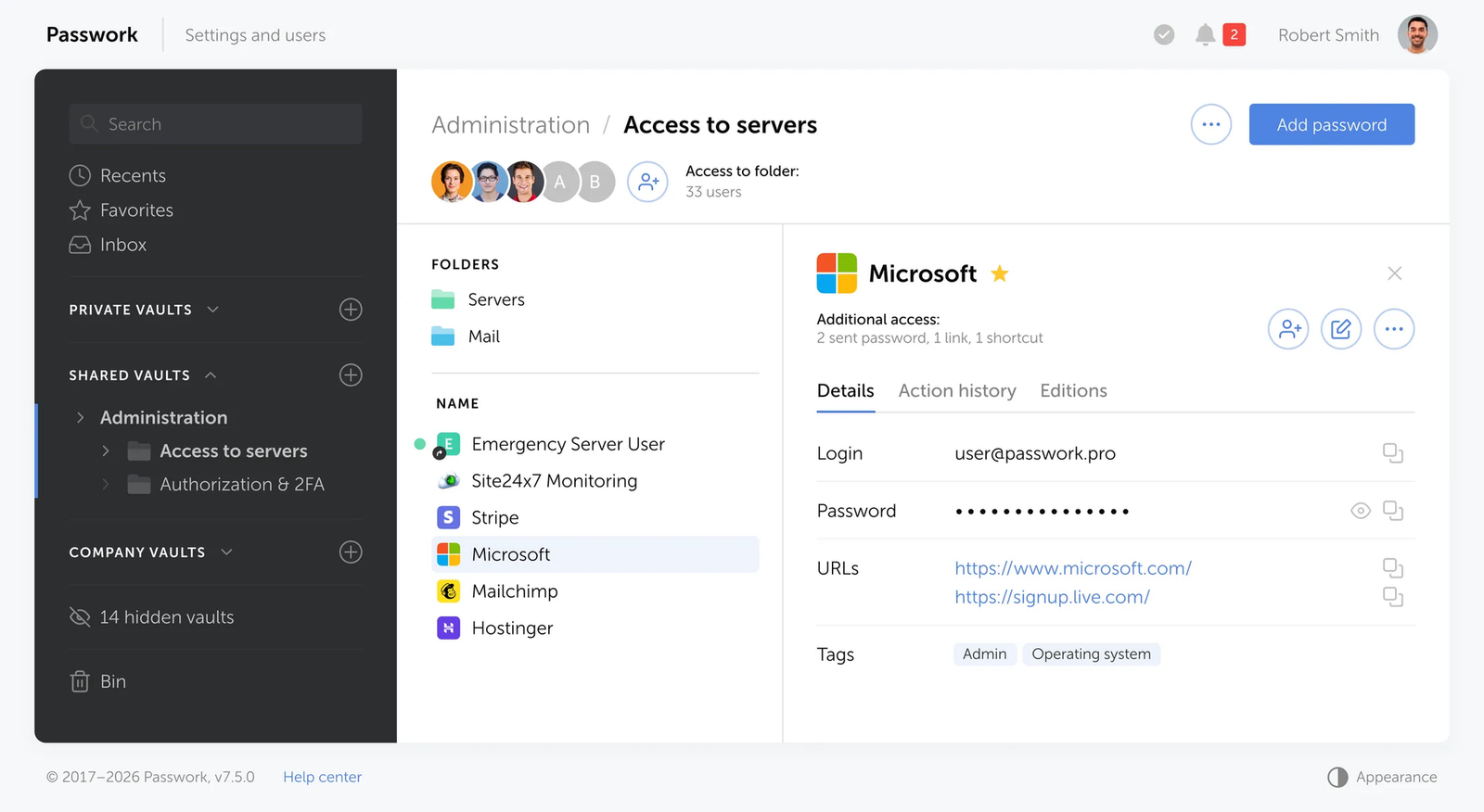
Hartcodierte Secrets erscheinen, wenn Teams keinen bequemen, zuverlässigen Ort haben, um Anmeldedaten zu speichern und zur Laufzeit abzurufen. Passwork beseitigt diese Lücke. Es handhabt jeden Anmeldedatentyp, den eine Organisation verwaltet – Benutzerpasswörter, geteilte Admin-Konten, API-Schlüssel, Datenbank-Verbindungszeichenketten, SSH-Schlüssel, TLS-Zertifikate und CI/CD-Tokens – mit der Speicherung, Zugriffskontrolle und dem Audit-Trail, die jede Kategorie erfordert.
Derselbe Tresor, in dem ein Betriebsteam Admin-Passwörter speichert, ist dasselbe System, das eine Deployment-Pipeline nach einer Datenbank-Verbindungszeichenkette abfragt. Ein Zugriffsmodell, ein Audit-Log, ein Rotations-Workflow.
Secrets speichern, damit sie nie hartcodiert werden müssen
Passwork organisiert Anmeldedaten in einer strukturierten Tresor-Hierarchie. Teams ordnen Secrets nach Umgebung und Kategorie – infrastructure/production/databases, services/stripe, servers/ssh-keys – und jede Ebene trägt unabhängige Zugriffskontrollen. Ein Secret im richtigen Tresor hat einen benannten Eigentümer, ein Umgebungs-Tag und einen definierten Satz von Konsumenten. Secrets ohne Eigentümer sind diejenigen, die letztendlich in Repositories committet werden.
Benutzerdefinierte Felder unterstützen benannte Secrets direkt: AWS_SECRET_KEY, STRIPE_SECRET, REDIS_AUTH, OAUTH_CLIENT_SECRET. Diese Benennung fließt in den CLI- und SDK-Abruf ein, macht den Tresor selbstdokumentierend und eliminiert die Konfigurationsverwirrung, die Entwickler dazu bringt, einen Wert „nur fürs Erste" hartzucodieren.
CLI-Injection: Die direkte Alternative zu hartcodierten Umgebungsvariablen
passwork-cli exec führt jeden Befehl mit als Umgebungsvariablen injizierten Secrets aus, nur für die Dauer dieses Befehls. Die Anmeldedaten erscheinen nicht in der Shell-Historie, werden nicht auf die Festplatte geschrieben und bleiben nach dem Beenden des Kindprozesses nicht bestehen.
# Run deploy script — secrets exist only for the duration of this command
passwork-cli exec --folder-id "$PROD_SECRETS_FOLDER_ID" ./deploy.sh
Dies ersetzt die .env-Datei, die in ein Repository committet wurde, den hartcodierten Wert, der aus einer Chat-Nachricht eingefügt wurde, und die Umgebungsvariable, die in der CI-Ausgabe gedruckt wird. Die Anwendung liest ihre Konfiguration wie vorgesehen aus der Umgebung; der Unterschied ist, woher diese Werte kommen.
Für einen einzelnen Wert in einem Shell-Skript:
DB_PASS=$(passwork-cli get --password-id "$ITEM_ID")
# DB_PASS is available in this shell, never written to disk
Für die Rotation – Aktualisierung der Anmeldedaten nach deren Änderung im Zielsystem:
passwork-cli update --password-id "$ITEM_ID" --password "$NEW_PASS"
Die CLI handhabt Entschlüsselung und Neuverschlüsselung lokal. Passworks Server speichert nur Chiffretext. Selbst eine vollständige Server-Kompromittierung liefert nichts Lesbares.
CI/CD-Integration ohne Hartcodierung von Pipeline-Tokens
CI/CD-Pipelines sind eine Hauptquelle für hartcodierte Secrets – Tokens und Verbindungszeichenketten, die direkt in Pipeline-Dateien committet werden, weil es keine bessere Option gab. Passwork bietet diese Option.
Das Docker-Image passwork/passwork-cli läuft als Job-Image in GitLab CI, GitHub Actions und Bitbucket Pipelines. Die Pipeline speichert nur drei Bootstrap-Anmeldedaten im Secret-Speicher der CI-Plattform: PASSWORK_HOST, PASSWORK_TOKEN und PASSWORK_MASTER_KEY. Alles andere lebt in Passwork.
# GitLab CI — no credentials in the pipeline file
deploy_prod:
image: passwork/passwork-cli:latest
script:
- passwork-cli exec --folder-id "$SECRETS_FOLDER_ID" ./deploy.sh
# GitHub Actions — credentials injected from platform secrets only
- name: Deploy with secrets
run: |
docker run --rm \
-e PASSWORK_HOST="${{ secrets.PASSWORK_HOST }}" \
-e PASSWORK_TOKEN="${{ secrets.PASSWORK_TOKEN }}" \
-e PASSWORK_MASTER_KEY="${{ secrets.PASSWORK_MASTER_KEY }}" \
passwork/passwork-cli:latest \
exec --folder-id "${{ vars.SECRETS_FOLDER_ID }}" ./deploy.sh
Für Kubernetes unterstützt Passwork einen Init-Container, der Secrets abruft, bevor die Hauptanwendung startet, und einen Sidecar, der sie nach der Rotation aktualisiert – ohne den Pod neu zu starten.
Dienstkonten: Maschinenidentität ohne Ausbreitung von Anmeldedaten
Jede CI/CD-Pipeline oder jedes Automatisierungsskript, das auf Passwork zugreift, verwendet ein dediziertes Dienstkonto mit eigener Rolle, eigenem Token-Paar und Zugriff nur auf die Tresore, die es tatsächlich benötigt. Eine Deployment-Pipeline erhält Nur-Lese-Zugriff auf Produktions-Secrets. Ein Rotationsskript erhält Lese-Schreib-Zugriff auf den Datenbank-Ordner. Wenn eine Pipeline außer Betrieb genommen wird, wird ihr Dienstkonto entfernt.
API-Tokens haben konfigurierbare Lebensdauern. Für einen CI/CD-Job, der minutenlang läuft, lebt das Zugriffstoken 15-60 Minuten. Für einen immer aktiven Rotationsdienst läuft das Zugriffstoken 1-4 Stunden und das Refresh-Token 30 Tage. Die Token-Paar-Rotation erfolgt programmatisch über POST /api/v1/sessions/refresh, sodass die Bootstrap-Anmeldedaten nie dauerhaft langlebig werden.
Zugriffskontrolle, die abbildet, wie Teams tatsächlich arbeiten
Passworks Berechtigungsmodell funktioniert sowohl auf Tresor- als auch auf Ordnerebene. Berechtigungen werden im Ordnerbaum vererbt, können aber auf jeder Ebene überschrieben werden. Das Plattform-Team hat vollständigen Zugriff auf infrastructure/production. Entwickler greifen auf infrastructure/development zu. Das CI/CD-Dienstkonto erhält Nur-Lese-Zugriff auf den benötigten Produktionsordner.
Rollenbasierter Zugriff, Gruppen und AD/LDAP-Synchronisierung bedeuten, dass wenn ein Ingenieur einem Team beitritt, er den Tresor-Zugriff der Gruppe erbt. Wenn er geht, wird der Zugriff einmal entfernt. Das Sicherheits-Dashboard markiert Anmeldedaten als kompromittiert, wenn sie nach dem Widerruf des Benutzerzugriffs nicht rotiert wurden – direkte Erkennung des Fehlermodus, der aktive exponierte Secrets produziert.
Passwort-Komplexitätsrichtlinien setzen Mindestanforderungen für Masterpasswörter und Authentifizierungspasswörter durch. Kontosperrungsrichtlinien begrenzen fehlgeschlagene Anmeldeversuche. SAML SSO bindet den Tresor-Zugriff an den bestehenden Identity-Provider, sodass die Passwork-Authentifizierung demselben Lebenszyklus wie jedes andere Unternehmenssystem folgt.
Audit-Trail und Zero-Knowledge-Architektur
Jeder Lese-, Schreib- und Berechtigungsänderungs-Vorgang wird aufgezeichnet: welches Konto, welche Anmeldedaten, welche Aktion, zu welchem Zeitstempel. Dienstkonten erscheinen im Log unter ihrer eigenen Identität. Das Log wird im CEF-Format für SIEM-Integration exportiert, sodass Passworks Zugriffshistorie in dieselbe Sicherheitsüberwachungsplattform wie Netzwerk- und Endpunkt-Ereignisse einfließt.
Verschlüsselung und Entschlüsselung erfolgen auf dem Client – im Browser, in passwork-cli oder im SDK. Der Server speichert nur Chiffretext. Passwork-Administratoren und Datenbankbetreiber haben keine technische Möglichkeit, gespeicherte Secrets zu lesen, selbst mit direktem Datenbankzugriff. Bei selbst gehosteten Bereitstellungen transitieren verschlüsselte Anmeldedaten niemals ein Drittanbietersystem. Passwork ist ISO 27001-zertifiziert und konform mit DSGVO und NIS2.
Checkliste zur Prävention hartcodierter Secrets
Keine einzelne Kontrolle ist ausreichend. Die folgenden Punkte decken Richtlinien, Werkzeuge und Prozesse ab – alle drei Ebenen müssen vorhanden sein, bevor die Checkliste vollständig ist.
Fazit

Hartcodierte Secrets sind eine vermeidbare Form der Exposition von Anmeldedaten. Die technischen Kontrollen existieren: Secrets-Manager, Pre-Commit-Hooks, CI/CD-Scanning, kurzlebige Anmeldedaten und Zugriff nach minimalen Berechtigungen. Der schwierigere Teil ist der Aufbau des Workflows, der sichere Praktiken zum Weg des geringsten Widerstands für jeden Entwickler bei jedem Commit macht.
Die vollständige Verteidigung ist mehrschichtig. Sichere Speicherung für Maschinen-Secrets. Scanning in jeder Phase der Pipeline. Rotationsrichtlinien mit definierten Eigentümern und SLAs. Entwickler-Workflow-Vorlagen, die die Reibung beseitigen, die zu Abkürzungen führt. Und Zugriffs-Governance für die menschlichen Anmeldedaten, die außerhalb des Anwendungscodes leben – die geteilten Admin-Passwörter, Dienstkonto-Anmeldedaten und Team-Zugriffstokens, die dazu neigen, sich über informelle Kanäle zu verbreiten, wenn keine bessere Option existiert.
Passwork gibt Teams ein einziges System zur Speicherung, zum Zugriff, zur Rotation und zur Prüfung jedes Anmeldedatentyps. Entwickler rufen Secrets zur Laufzeit ab, anstatt sie in Code einzufügen. Pipelines ziehen aus einem Vault, anstatt aus committeten Dateien zu lesen. Betriebsmitarbeiter verwalten geteilte Admin-Passwörter auf derselben Plattform, auf der DevOps Infrastruktur-Secrets handhabt. Wenn Anmeldedaten in einem Repository gefunden werden, beginnt die Reaktion in Passwork: den alten Wert widerrufen, den neuen generieren, abhängige Systeme aktualisieren und über das Audit-Log bestätigen, dass die alten Anmeldedaten nicht mehr verwendet werden.
Wenn Ihr Team weiterhin Service-, Admin- oder Projekt-Passwörter über informelle Kanäle teilt, beginnen Sie damit, sie in Passwork zu zentralisieren und zu definieren, wer jede Anmeldedaten abrufen, rotieren und überprüfen darf. Diese einzelne Änderung beseitigt eine Risikokategorie, die kein Code-Scanning erfassen wird. Passwork kostenlos testen
Häufig gestellte Fragen

Was ist ein Beispiel für ein hartcodiertes Secret?
Ein Datenbank-Passwort, das direkt in eine Quelldatei geschrieben wurde, ein AWS-Zugriffsschlüssel in einer .yaml-Konfiguration, ein privater SSH-Schlüssel in einem Deployment-Skript oder ein JWT-Signatur-Secret im Anwendungscode. Jede Anmeldedaten, die als statischer Wert in Code, einer Konfigurationsdatei, einem Skript oder einem kompilierten Anwendungspaket eingebettet ist, qualifiziert als hartcodiertes Secret.
Sind hartcodierte Secrets dasselbe wie hartcodierte Passwörter?
Hartcodierte Passwörter sind eine Art von hartcodierten Secrets. Die breitere Kategorie umfasst auch API-Schlüssel, OAuth-Tokens, SSH-Schlüssel, private Zertifikate, TLS-Schlüsselmaterial, Verschlüsselungsschlüssel und Datenbank-Verbindungszeichenketten. MITREs CWE-798 deckt die gesamte Klasse unter „Verwendung von hartcodierten Anmeldedaten" ab.
Ist es sicher, Secrets in privaten Repositories zu speichern?
Nein. Private Repositories reduzieren die öffentliche Exposition, machen Secrets aber nicht sicher. Der Zugriff steht oft vielen Entwicklern, automatisierten Tools und Integrationen zur Verfügung. Kompromittierte Entwicklerkonten, falsch konfigurierte Berechtigungen, CI/CD-Pipelines, Backups, Forks und lokale Klone erweitern alle die Angriffsfläche über das hinaus, was „privat" impliziert.
Reicht es aus, ein hartcodiertes Secret aus dem Code zu löschen?
Nein. Wenn das Secret committet wurde, kann es weiterhin in der Git-Historie, in Forks, CI/CD-Logs, Build-Artefakten, lokalen Klonen und Backups existieren. Rotieren oder widerrufen Sie die Anmeldedaten zuerst. Entfernen Sie sie dann aus der Codebasis und bereinigen Sie die Repository-Historie, wenn der Umfang der Exposition dies erfordert.
Reichen Umgebungsvariablen aus, um hartcodierte Secrets zu verhindern?
Umgebungsvariablen helfen, Konfiguration vom Code zu trennen, sind aber keine vollständige Kontrolle. Teams benötigen weiterhin sichere Speicherung für diese Werte, Zugriffskontrollen, Rotationsrichtlinien und Schutz vor Leaks in Logs oder Build-Artefakten. Umgebungsvariablen reduzieren das Risiko von Secrets in Quelldateien; sie ersetzen keine Secrets-Management-Strategie.
Wie lange bleiben geleakte Secrets typischerweise aktiv?
Laut GitGuardians State of Secrets Sprawl 2026-Bericht waren 64 % der 2022 als gültig bestätigten Secrets 2026 noch aktiv und ausnutzbar. Der Verizon 2025 DBIR fand eine mediane Behebungszeit von 94 Tagen für entdeckte Secrets auf GitHub. Lange Lebensdauern von Anmeldedaten sind der Hauptgrund, warum ein einziges geleaktes Secret anhaltenden Schaden verursachen kann.


Was sind hartcodierte Geheimnisse und warum sind sie so riskant?
Hartcodierte Geheimnisse sind Zugangsdaten, die direkt in den Code geschrieben werden, anstatt zur Laufzeit injiziert zu werden.