Which words pop into your head when creating a password for your new account on a website or on a social network? Safety? Privacy? Well, there’s some bad news for you here — in our digital world, hackers are clued-up on hacking any kind of password that you can think into existence, and as a matter of fact, it’s a global problem. Users of the internet can never be sure that their accounts are protected enough to prevent data theft. Even global organizations such as Facebook can be the subject of cyber-attacks. And we mention the social giant for good reason too — in March 2020, the British company Comparitech stated that the data of more than 267 million people was leaked.
Ergo, it’s of paramount importance to know which techniques cybercriminals use to hack your password and steal your private information. There are a great number of methods that hackers can use to deceive people in order to steal private credentials and data. That’s why, today, we’re going through the most common techniques that can be used, so you’ll be in the know and much more secure online as a result.
1. Phishing
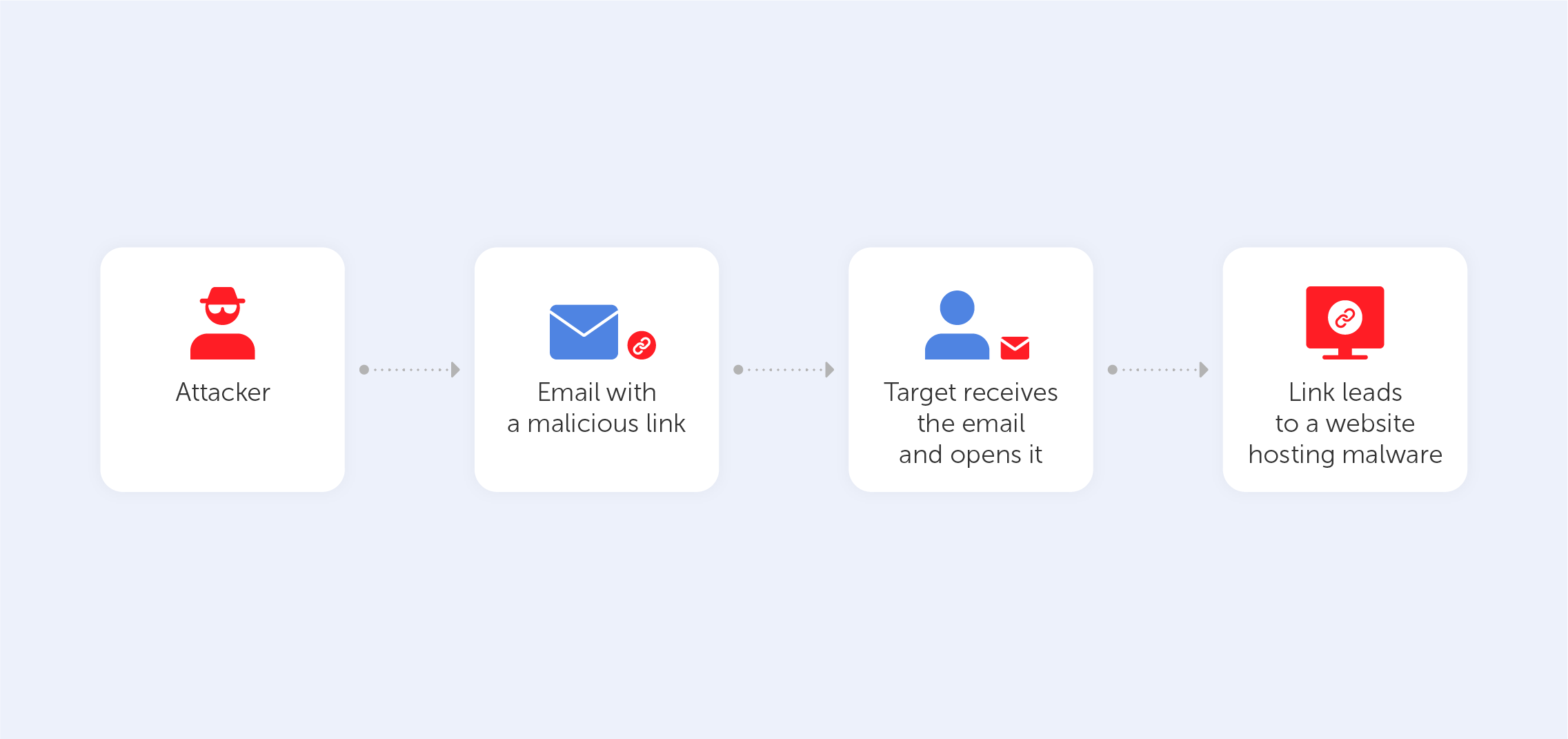
The easiest and most common way of hacking someone’s password is phishing. There are plenty of techniques here: phishing can take the form of an email, an SMS, a direct message on a social media platform, or a public post on a website. Cybercriminals spread a link or attachment that hooks an internet user in. Pushing leads a victim to a fake log-in page where he or she has to enter their data. After hacking, the hackers get a variety of data that can be used for any purpose. This way, people get their sensitive information served on a silver platter. As this technique is one of the oldest ones in the book, most users are aware of such a ploy. Almost everyone knows that following a suspicious link on the internet is a sure way of compromising yourself. Indeed, that’s why emails from unknown addresses tend to fall straight into the spam box and we’re used to blocking unknown numbers.
2. Social engineering
This type of cyberattack is based on the mistakes and imprudence that come as standard with the human brain. A criminal tricks the victim by acting like he or she is a real agent of an official company. It might be a fake call from your bank or some kind of technical support branch. You’ll likely be asked to provide confidential data so that the ‘agent’ may investigate ‘suspicious activity’ on your bank account. Usually, social engineering is mostly successful in manipulating pensioners due to their often dull mental blade and trusting nature. This technique is quite widespread and is much easier than creating an entire fake website to phish someone’s password.
3. Brute force attack
Brute force attacks are best characterized by the long, heavy method of checking each possible password variant. This way is really time-consuming, so most hackers use special software to automate the process. Most of the time, such attacks are based on knowledge gained from previous cracks as users often reuse their passwords on multiple websites and platforms. Also, cybercriminals might try lists of common variations of letters and numbers. That’s why, to protect yourself from such attacks, you should use as many symbols as possible and create passwords from unconnected words and unpredictable alpha-numerical compilations. Alternatively, you could use a password manager to automate this struggle (nudge nudge).
4. Dictionary attack
The dictionary attack partly resembles the previous method (brute force attack), the main idea of such a cyber attack is to submit all possible password variations by taking words from the dictionary. It makes the process of researching the right combination easier due to the strict structure of the dictionary. Moreover, it takes less time to crack the password If the hacker knows some sensitive information about the victim, like the name of their child, pet, or favorite color, for instance. Indeed, predictable human nature is the reason why this is such an effective method. To eliminate the possibility of such a cyberattack, it’s worth mixing semantically unconnected words, numerals, and other symbols. The best way, of course, is to get a password manager (nudge nudge).
5. Rainbow table attack
Passwords stored on the victim’s computer are usually encrypted. The plain text is replaced by various strings (hashes) to prevent data leaks. This method is named ‘hashing’. However, this method doesn’t guarantee that the password won’t be cracked; hackers are very familiar with such multi-layer security. The ‘rainbow table’ is a list of passwords and their hashes that have already been acquired through previous attacks. Hackers try to decrypt hashes by figuring out the correct combination based on different variations from the rainbow table. As a result, the password’s code may be retrieved from the database, removing the necessity to hack it. A good way to mitigate the risks of such an attack is to use software that includes randomly generated data in the password before hashing it.
6. Spidering
Many companies base their passwords on the names of the products they produce to help their staff remember the credentials that they need to access corporate accounts. Spidering is a type of cyberattack that uses this information to hack the company’s system and exploit the obtained information for malicious purposes. They surf the sites of organizations and learn about their businesses. Then, this knowledge is used to make a list of keywords that can be exploited in brute force attacks. As this process is quite time-consuming, experienced hackers utilize automatic software such as the infamous ‘web crawler’.
7. Malware
Malware is a harmful kind of software created to steal private information from the computer that it has been installed on. The victim gives access to his or her computer by clicking on a link specially made by cybercriminals. While this technique has various forms, the most common are keyloggers and screen scrapers that take a video of a user's screen or screenshots when passwords are being entered. They then send this data to the hacker. Some kinds of malware can encrypt a system’s data and prevent users from accessing certain programs. Others can look through users’ data to find a password dictionary that can be used in a variety of ways.
The amount of techniques being used by hackers to crack our passwords is increasing exponentially. The more ways there are to prevent break-ins, the more work hackers ought to do to get around them. That’s why, you should leave it to us, Passwork, your neighborly password managing wizards, to lift the burden from your shoulders.
The brute force attack: definition and examples
What is a brute force attack? Among a myriad of different cyberattacks, the brute force attack seems to be the most common and primitive way of hacking. This technique involves guessing login information through trial-and-error, where hackers try all conceivable combinations in the hope of guessing correctly. The term “brute
Insider threats: Prevention vs. privacy
Insider threats are a major cybersecurity risk, often overlooked. Prevention requires balancing trust and security focus on monitoring risk-based behaviors, not constant surveillance. Use AI for early detection, educate staff, and be transparent to foster trust while protecting data.

5 ways to keep your business safe from cyber threats
In an era where cybercrime is rampant, businesses must take a proactive approach to safeguard their confidential information. In 2021 alone, over 118 million people have been affected by data breaches, and this number is expected to rise exponentially. In this post, we’ll discuss some of the best practices

Password-cracking techniques used by hackers
If you've heard of ‘SHA’ in various forms but aren't sure what it stands for or why it's essential — you’re in luck! We'll attempt to shed some light on the family of cryptographic hash algorithms today.
But, before we get into SHA, let's go over what a hash function is and how it works. Before you can comprehend what SHA-1 and SHA-2 are, you must first grasp these principles.
Let's get started.
What Is a hash function?
A hash function relates to a set of characters (known as a key) of a certain length. The hash value is a representation of the original string of characters, however, it is usually smaller.
Because the shorter hash value is simpler to search for than the lengthier text, hashing is used for indexing and finding things in databases. Encryption employs hashing as well.
SHA-1, SHA-2, SHA-256… What’s this all about?
There are three types of secure hash algorithms: SHA-1, SHA-2, and SHA-256. The initial iteration of the algorithm was SHA-1, which was followed by SHA-2, an updated and better version of the first. The SHA-2 method produces a plethora of bit-length variables, which are referred to as SHA-256. Simply put, if you see “SHA-2,” “SHA-256” or “SHA-256 bit,” those names are referring to the same thing.
The NIST's Formal Acceptance
FIPS 180-4, published by the National Institute of Standards and Technology, officially defines the SHA-256 standard. Moreover, a set of test vectors is included with standardization and formalization to confirm that developers have correctly implemented the method.
Let’s break down the algorithm and how it works:
1. Append padding bits
The first step in our hashing process is to add bits to our original message to make it the same length as the standard length needed for the hash function. To accomplish so, we begin by adding a few details to the message we already have. The amount of bits we add is determined so that the message's length is precisely 64 bits less than a multiple of 512 after these bits are added. This can be expressed mathematically in the following way:
n x 512 = M + P + 64
M is the original message's length.
P stands for padded bits.
2. Append length bits
Now that we've added our padding bits to the original message, we can go ahead and add our length bits, which are equal to 64 bits, to make the whole message an exact multiple of 512.
We know we need to add 64 extra bits, so we'll compute them by multiplying the modulo of the original message (the one without the padding) by 232. We add those lengths to the padded bits in the message and get the complete message block, which must be a multiple of 512.
3. Initialize the buffers
We now have our message block, on which we will begin our calculations in order to determine the final hash. Before we get started, I want to point out that we'll need certain default settings to get started with the steps we'll be taking.
a = 0x6a09e667
b = 0xbb67ae85
c = 0x3c6ef372
d = 0xa54ff53a
e = 0x510e527f
f = 0x9b05688c
g = 0x1f83d9ab
h = 0x5be0cd19
Keep these principles in the back of your mind for now; all will fit together in the following phase. There are a further 64 variables to remember, which will operate as keys and are symbolized by the letter 'k.'
Let's go on to the portion where we calculate the hash using these data.
4. Compression Function
As a result, here is where the majority of the hashing algorithm is found. The whole message block, which is 'n x 512' bits long, is broken into 'n' chunks of 512 bits, each of which is then put through 64 rounds of operations, with the result being provided as input for the next round of operations.
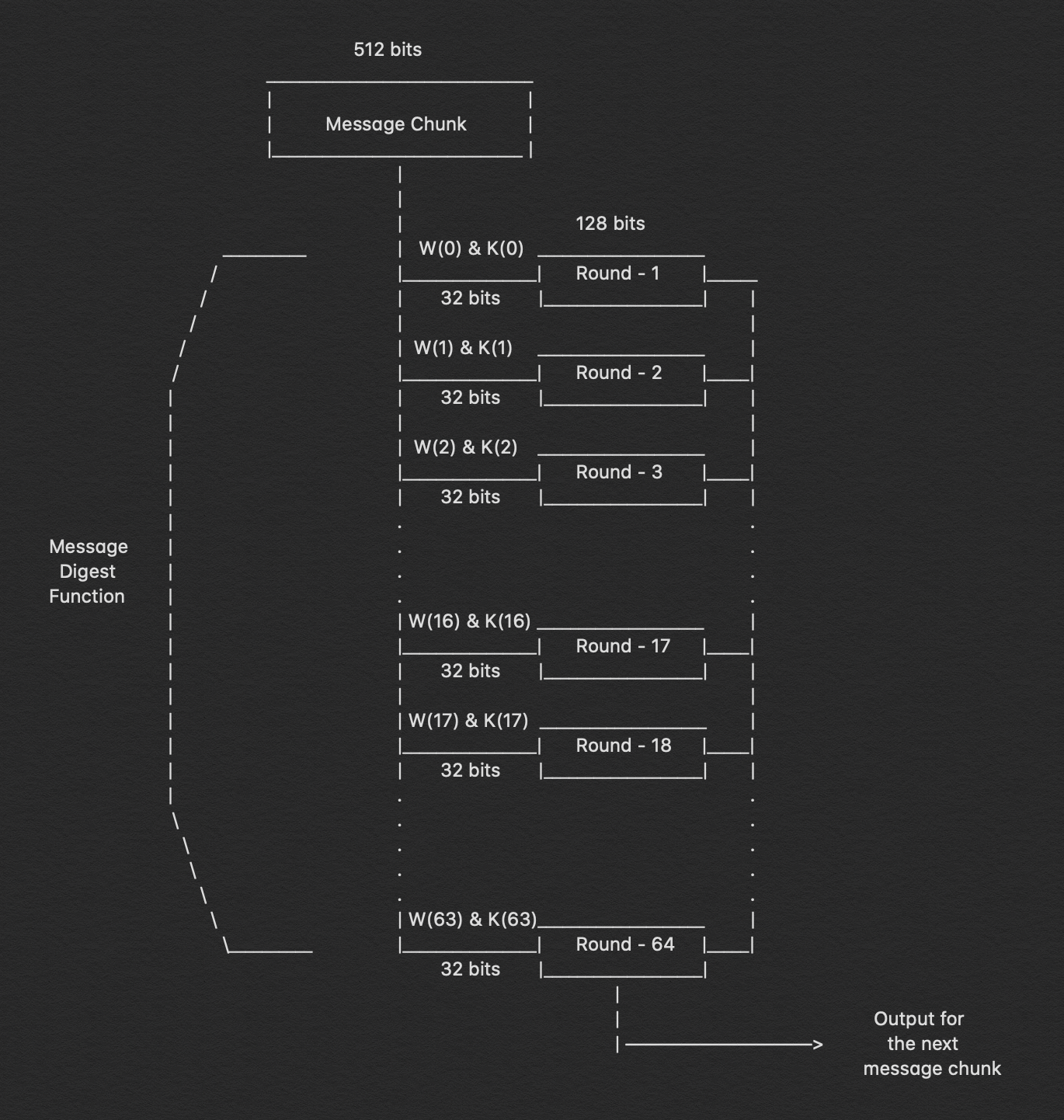
The 64 rounds of operation conducted on a 512-bit message are plainly visible in the figure above. We can see that we send in two inputs: W(i) and K(i). During the first 16 rounds, we further break down the 512-bit message into 16 pieces, each consisting of 32 bits. Indeed, we must compute the value for W(i) at each step.
W(i) = Wⁱ⁻¹⁶ + σ⁰ + Wⁱ⁻⁷ + σ¹
where,
σ⁰ = (Wⁱ⁻¹⁵ ROTR⁷(x)) XOR (Wⁱ⁻¹⁵ ROTR¹⁸(x)) XOR (Wⁱ⁻¹⁵ SHR³(x))
σ¹ = (Wⁱ⁻² ROTR¹⁷(x)) XOR (Wⁱ⁻² ROTR¹⁹(x)) XOR (Wⁱ⁻² SHR¹⁰(x))
ROTRⁿ(x) = Circular right rotation of 'x' by 'n' bits
SHRⁿ(x) = Circular right shift of 'x' by 'n' bits
5. Output
Every round's output is used as an input for the next round, and so on until just the final bits of the message are left, at which point the result of the last round for the nth portion of the message block will give us the result, i.e. the hash for the whole message. The output has a length of 256 bits.
Conclusion
In a nutshell, the whole principle behind SHA would sound something like this:
We determine the length of the message to be hashed, then add a few bits to it, beginning with '1' and continuing with '0' and then ‘1’ again until the message length is precisely 64 bits less than a multiple of 512. By multiplying the modulo of the original message by 232, we may add the remaining 64 bits. The complete message block may be represented as 'n x 512' bits after the remaining bits are added. Now, we split each of these 512 bits into 16 pieces, each of 32 bits, using the compression function, which consists of 64 rounds of operations. For the first 16 rounds, these 16 sections, each of 32 bits, operate as input, and for the next 48 rounds, we have a technique to compute the W(i). We also include preset buffer settings and 'k' values for each of the 64 rounds. We can now begin computing hashes since we have all of the necessary numbers and formulae. The hashing procedure is then repeated 64 times, with the result of the i round serving as the input for the i+1 round. As a result, the output of the 64th operation of the nth round will be the output, which is the hash of the whole message.
The SHA-256 hashing algorithm is now one of the most extensively used hashing algorithms since it has yet to be cracked and the hashes are generated rapidly when compared to other safe hashes such as the SHA-512. It is well-established, but the industry is working to gradually transition to SHA-512, which is more secure, since experts believe SHA-256 may become susceptible to hacking in the near future.
Cloud security: Shared responsibility or shared confusion?
Introduction Cloud security remains one of the most debated topics in modern IT. As organizations continue their migration to cloud platforms, the question of “Who is responsible for what?” grows increasingly complex. In our latest Passwork webinar, cybersecurity lecturer David Gordon joined host Turpal to unpack the realities behind the

What is quantum cryptography?
If the concept of ‘quantum cryptography’ sounds complicated to you, you’re
right. That’s why this ‘encryption tutorial for dummies’ shall demystify the
concept and provide an explanation in layman’s terms. Quantum cryptography, which has been around for a few decades, is becoming more
and more important to our
Passwork: Secrets management and automation for DevOps
Introduction In corporate environment, the number of passwords, keys, and digital certificates is rapidly increasing, and secrets management is becoming one of the critical tasks for IT teams. Secrets management addresses the complete lifecycle of sensitive data: from secure generation and encrypted storage to automated rotation and audit trails. As

How SHA-256 works
If the concept of ‘quantum cryptography' sounds complicated to you, you're right. That’s why this ‘encryption tutorial for dummies’ shall demystify the concept and provide an explanation in layman’s terms.
Quantum cryptography, which has been around for a few decades, is becoming more and more important to our daily lives because of its ability to protect essential data in a manner that conventional encryption techniques cannot.
What is it?
Cryptography, as we all know, is a technique that aims to encrypt data by scrambling plain text so that only those with the appropriate ‘key’ can read it. By extension, quantum cryptography encrypts data and transmits it in an unhackable manner using the principles of quantum mechanics.
While such a concept seems straightforward, the intricacy resides in the quantum mechanics that underpin quantum cryptography. For example:
- The particles that make up the cosmos are fundamentally unpredictable, and they may exist in several places or states of existence at the same time;
- A quantum attribute cannot be measured without causing it to change or be disturbed;
- Some quantum attributes of a particle can be cloned, but not the whole particle.
How does it work?
Theoretically, quantum cryptography operates by following a model that was first published in 1984.
Assume there are two people called Alice and Bob who want to communicate a message in a safe manner, according to the model of quantum cryptography. Alice sends Bob a key, which serves as the signal for the communication to begin. One of the most important components is a stream of photons that go in just one direction. Each photon corresponds to a single bit of data — either a 0 or a 1 — in the computer's memory. However, in addition to traveling in a straight path, these photons are oscillating, or vibrating, in a certain fashion as they move.
The photons pass via a polarizer before reaching Alice, the sender, who then commences the transmission. When some photons pass through a polarizer with the same vibrations as before, and when others pass through with different vibrations, the filter is said to be ‘polarized’. There are many polarization states to choose from, including vertical (1 bit), horizontal (0 bit), 45 degrees right (1 bit) and 45 degrees left (0 bit). In whatever system she employs, the broadcast has one of two polarizations, each encoding a single bit, which is either 0 or 1.
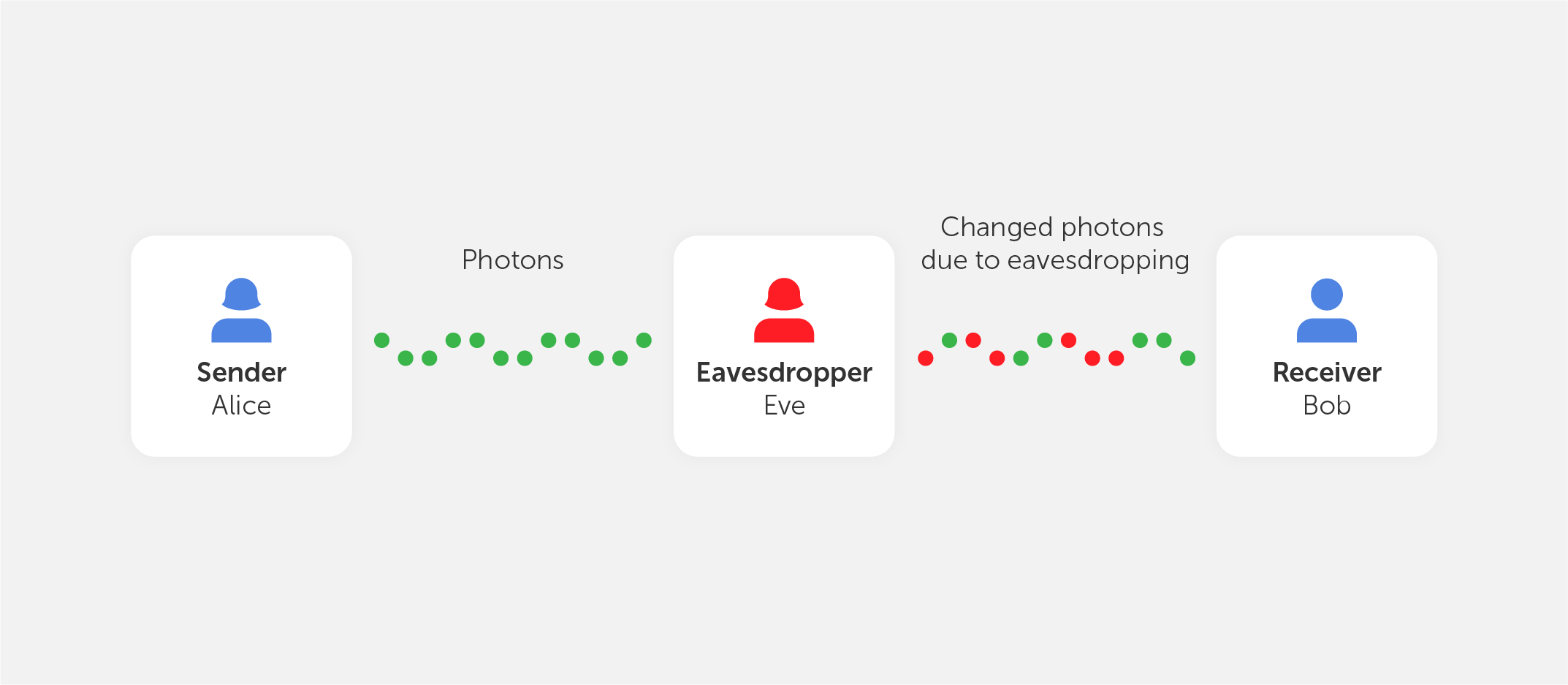
From the polarizer to the receiver, the photons are now traveling via optical fiber to Bob. Each photon is analyzed using a beam splitter, which determines the polarization of each photon. After receiving the photon key, Bob does not recognize the right polarization of the photons, so he chooses one polarization at random from a pool of available options. Alice now compares the polarizers Bob used to polarize the key and informs Bob of the polarizer she used to deliver each photon to the receiver. Bob checks to see whether he used the right polarizer at this point. The photons that were read with the incorrect splitter are then eliminated, and the sequence that is left is deemed the key sequence.
Let's pretend there is an eavesdropper present, who goes by the name of Eve. Eve seeks to listen in and has the same tools as Bob in order to do so successfully. However, Bob has the benefit of being able to converse with Alice in order to check which polarizer type was used for each photon, but Eve does not. Eve is ultimately responsible for rendering the final key.
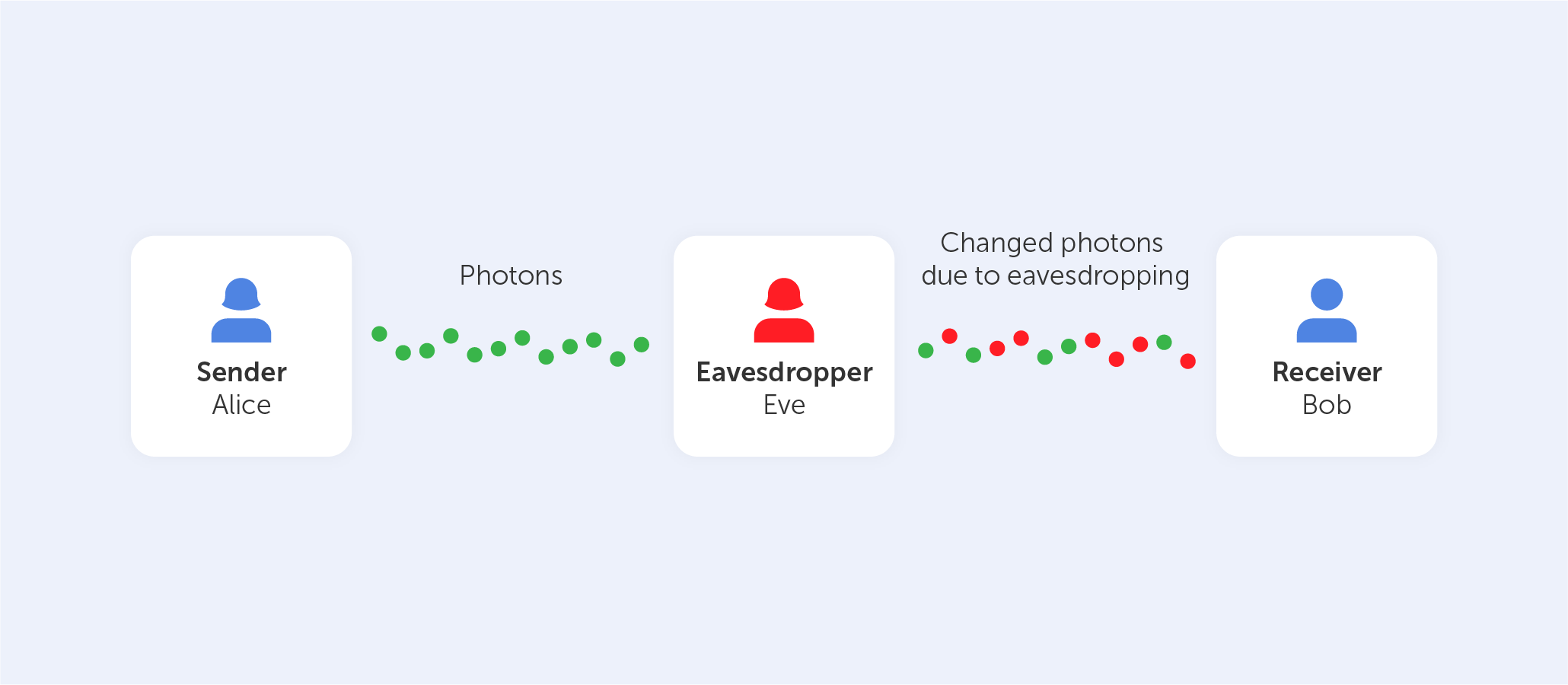
Alice and Bob would also be aware if Eve was listening in on their conversation. After Eve observes the flow of photons, the photon locations that Alice and Bob anticipate to see will be altered as a result of her observations.
Well, that’s all pretty mind-blowing, but for us, the general public, the biggest question is…
Is it really used?
Although the model described above has not yet been fully developed, there have been successful implementations of it, including the following:
- The University of Cambridge and the Toshiba Corporation collaborated to develop a high-bit-rate quantum key distribution system based on the BB84 quantum cryptography protocol;
- DARPA's Quantum Network, which operated from 2002 to 2007, was a 10-node QKD (Quantum Key Distribution) network constructed by Boston University, Harvard University, and IBM Research. It was operated by the Defense Advanced Research Projects Agency;
- Quantum Xchange created the first quantum network in the United States, which is comprised of over 1,000 kilometers of optical fiber;
- The development of commercial QKD systems was also carried out by commercial businesses such as ID Quantique, Toshiba, Quintessence Labs, and MagiQ Technologies Inc.
As you can see, these rare implementations are pretty far from what you’d expect to use every day. But hopefully, that will change in the near future.
The pros and cons of quantum cryptography
As with any developing technology, the state of it now (2022), may be very different to its state in the future. Thus, the following table may change dramatically. We do believe, however, that we’ll see fewer points in the ‘Limitations’ column as the years go on.

The need for unbreakable encryption is right there staring us down. The development of quantum computers is on the horizon, and the security of encrypted data is now in jeopardy due to the threat of quantum computing. We are fortunate in that quantum cryptography, in the form of QKD, provides us with the answer we need to protect our information long into the future — all while adhering to the difficult laws of quantum physics.
Python connector 0.1.5: Automated secrets management
The new Python connector version 0.1.5 expands CLI utility capabilities. We’ve added commands that solve critical tasks for DevOps engineers and developers — secure retrieval and updating of secrets in automated pipelines. What this solves Hardcoded secrets, API keys, tokens, and database credentials create security vulnerabilities and operational bottlenecks.

What is password hashing and salting?
Cryptography is both beautiful and terrifying. Perhaps a bit like your ex-wife.
Despite this, it represents a vital component of day-to-day internet security;
without it, our secrets kept in the digital world would be exposed to everyone,
even your employer. I doubt you’d want information regarding your sexual
preferences
Passwork: Secrets management and automation for DevOps
Introduction In corporate environment, the number of passwords, keys, and digital certificates is rapidly increasing, and secrets management is becoming one of the critical tasks for IT teams. Secrets management addresses the complete lifecycle of sensitive data: from secure generation and encrypted storage to automated rotation and audit trails. As

What is quantum cryptography?
End-to-end encryption has been introduced by many communication providers in recent years, notably WhatsApp and Zoom. Although those companies have tried to explain the concept to their user base several times, we believe they failed. Whilst it's clear that these platforms have increased security, most don’t know how or why. Well, encryption is a rather simple concept to understand: It converts data into an unreadable format. But what exactly does "end-to-end" imply? What are the advantages and disadvantages of this added layer of security? We'll explain this as simply as possible without diving too much into the underlying math and technical terminology.
What is end-to-end encryption?
End-to-end encryption (E2EE) is a state-of-the-art protocol for communication security. Only the sender and the intended recipient(s) have access to the data in an end-to-end encrypted system. The encrypted data on the server is inaccessible to both hackers and undesirable third parties.
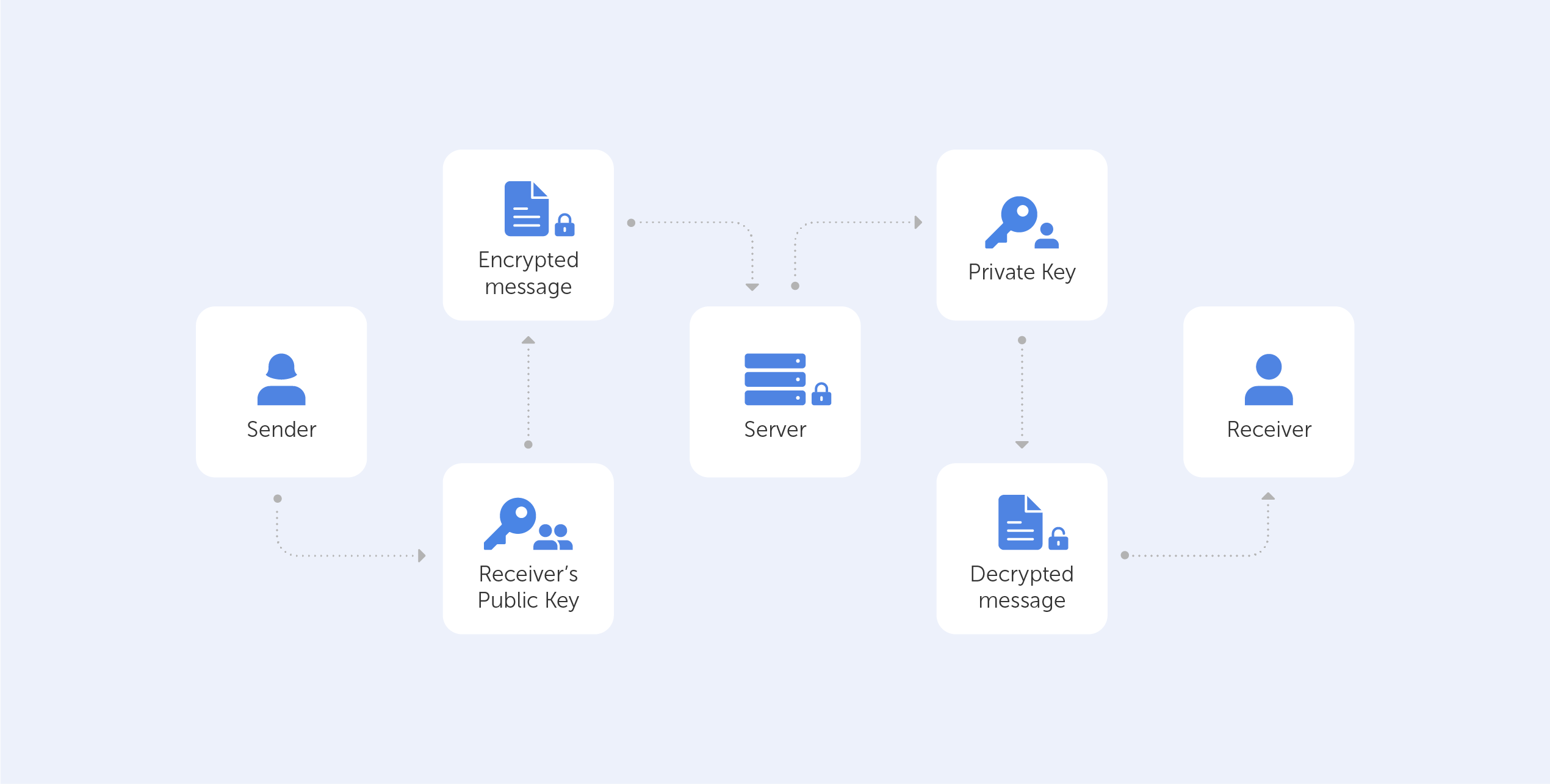
End-to-end encryption is best understood when compared to the encryption-in-transit approach, so let’s perform a quick recap. If a service employs encryption-in-transit, it is usually encrypted on your device before being delivered to the server. It’s then decrypted for processing on the server before it’s re-encrypted and routed to its final destination. When the data is in transit, it’s encrypted, but when it’s ‘at rest’, it’s decrypted. This safeguards the data during the most dangerous stage of the journey, transit — when it’s most exposed to hackers, interception, and theft.
End-to-end encryption, on the other hand, is the process of encrypting data on your device and not decrypting it until it reaches its destination. When your message travels through the server, not even the service that is delivering the data can view the content of your message.
In practice, this means that messengers using 'real' end-to-end encryption, like Signal, know only your phone number and the date of your last login – nothing more.
This is important for users that want to be sure their communication is kept secure from prying eyes. There are also some real-life examples that utilize end-to-end encryption for financial transactions and commercial communication.
How does it work?
The generation of a public-private key pair ensures the security of end-to-end encryption. This method, also known as asymmetric cryptography, encrypts and decrypts the message using distinct cryptographic keys. Public keys are widely distributed and are used to encrypt or ‘lock’ messages. Only the owner has access to the private keys, which are needed to unlock or decrypt the communication.
Whenever the user takes part in any end-to-end encrypted communication, the system automatically generates dedicated public and private keys.
If this sounds too complicated, here is a very simple metaphor:
You just bought a new Rolex for your buddy, who lives in Australia. Now, it’s already in a fancy green leather box, so you decide to put the stamp directly on it and send it. There is nothing wrong with that approach as long as you trust that the postal workers won’t steal it.
However, if you decide to put the Rolex box inside another box, hiding the nature of the gift from all interacting parties along the way, then you’ve effectively ensured (for all intents and purposes) that the Rolex is only visible to the intended recipient; when your mate from down under gets a hold of the box, he takes his pair of scissors and ‘decrypts’ the present. Indeed, you’ve ensured ‘end-to-end’ encryption.
You’re already using end-to-end encryption, daily
As we mentioned before, during an E2EE interaction, the server that delivers encrypted data between one "end" and the other "end" is unable to decode and read the data it sends. Even the servers' owners are unable to access the information since it is not saved on the servers themselves, only the "endpoints" (or the devices) of the discussion can decode the data.
If you’re daily using messengers like WhatsApp, iMessage, and Signal (where E2EE is enabled by default) or Telegram, Allo, and Facebook's ‘Secret Conversation’ function (where E2EE can be manually activated) – you’re already using end-to-end encryption.
What's more fascinating is that E2EE communication providers don't require you to trust them. And that’s great!
The fact that their systems can be hacked makes no difference to you because the transported data is encrypted and can only be read by the sender and receiver, which has enraged several organizations. There are known cases when such agencies asked for special ‘backdoors’ that would allow them to decrypt messages.
Why isn’t everything end-to-end encrypted?
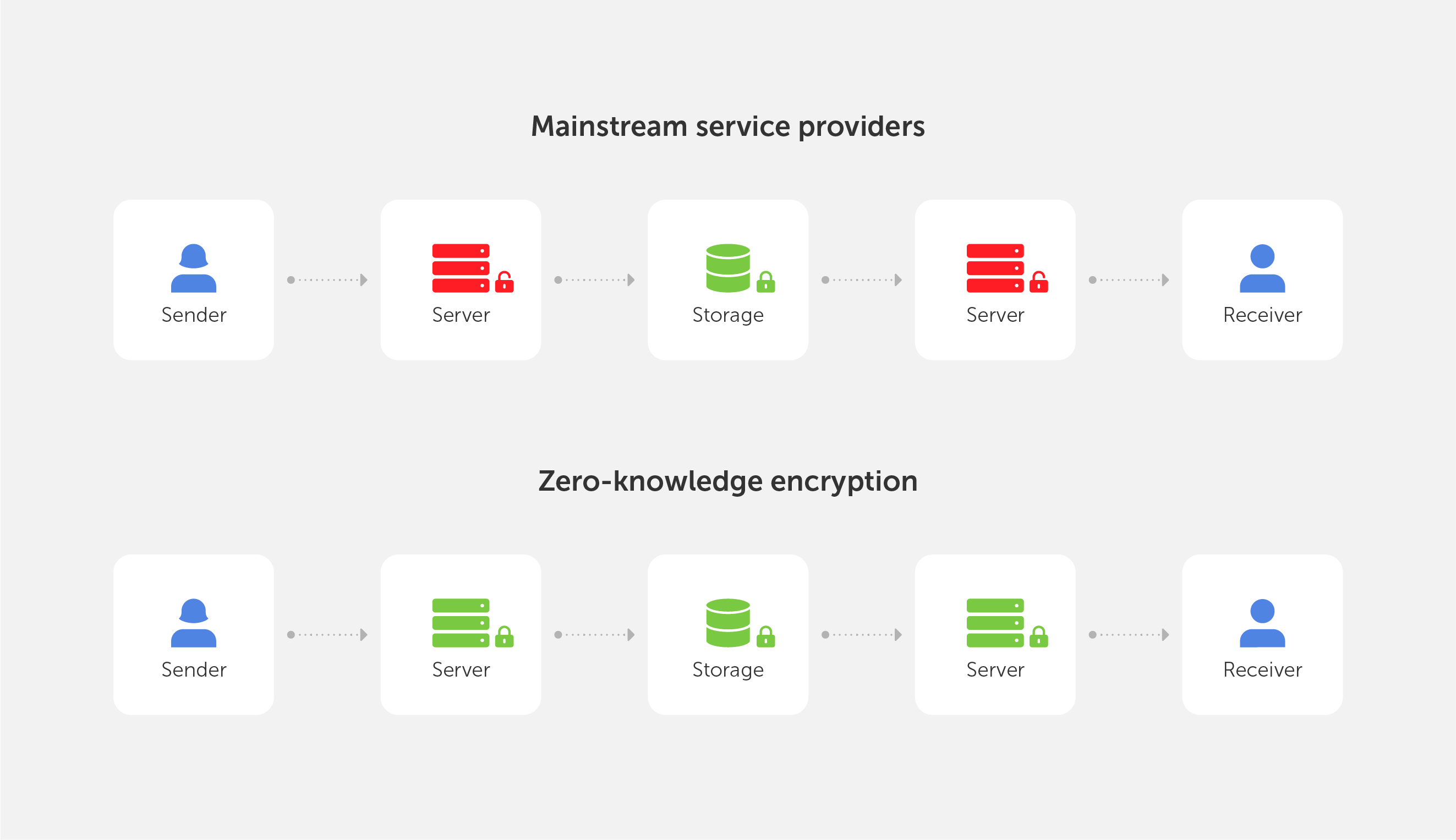
End-to-end encryption is theoretically sound, but it lacks flexibility, thus it can't be utilized when the "two ends" that communicate data don't exist, such as with cloud storage.
This is why Zero-Knowledge Encryption was created, a solution that overcomes the problem by hiding the encryption key, even from the storage provider, resulting in an authentication request without the requirement for password exchange.
Moreover, end-to-end encryption does not hide information about the message, such as the date and time it was sent or the people who participated in the conversation. This metadata might provide indications on where the 'end-point' might be – not great if you are the target of a hacker.
The biggest problem, however, is that in reality, we never know whether the communication is end-to-end encrypted. Providers may claim to provide end-to-end encryption when what they truly deliver is encryption-in-transit. The information might be kept on a third-party server that can be accessed by anybody who has access to the server.
Conclusion
While it’s obvious that you shouldn’t be shipping Dave’s Rolex in its fancy green box, the reality is, if you’ve nothing to hide and you’re not transporting something incredibly valuable, encryption-in-transit is up to the job.
End-to-end encryption is a wonderful technology that enables a high level of security when properly implemented. But it doesn't really tackle the main issue – the end-user, still, to this day, needs to trust the system that they’re using to communicate. We hope that the next generation of encryption technologies such as ZKP will be able to change that.
Password-cracking techniques used by hackers
Which words pop into your head when creating a password for your new account on a website or on a social network? Safety? Privacy? Well, there’s some bad news for you here — in our digital world, hackers are clued-up on hacking any kind of password that you can think
Passwork 7: Security verified by HackerOne
Passwork has successfully completed the penetration testing, carried out by HackerOne — the world’s largest platform for coordinating bug bounty programs and security assessments. This independent evaluation confirmed Passwork’s highest level of data protection and strong resilience against modern cyber threats. What the pentest covered Security architecture and data

Passwork: Secrets management and automation for DevOps
Introduction In corporate environment, the number of passwords, keys, and digital certificates is rapidly increasing, and secrets management is becoming one of the critical tasks for IT teams. Secrets management addresses the complete lifecycle of sensitive data: from secure generation and encrypted storage to automated rotation and audit trails. As

What is End-to-end encryption?
In this year of our lord, 2022, the term ‘Zero-Knowledge Encryption’ equates to best-in-class data insurance. We’ve already written an article named “What is Zero-Knowledge Proof?”, so we’re not going to look at definitions here, but rather, we’re going to explore the pros and cons of Zero-Knowledge proof encryption when compared to other technologies.
But for those who don’t want to dive deep into technical details, here’s an explanation of what Zero-Knowledge Encryption means:
It simply implies that no one else (not even the service provider) has access to your password-protected data.
This is important because even if your files are completely encrypted, if the server has access to the keys, a centralized hacker attack can result in a data breach.
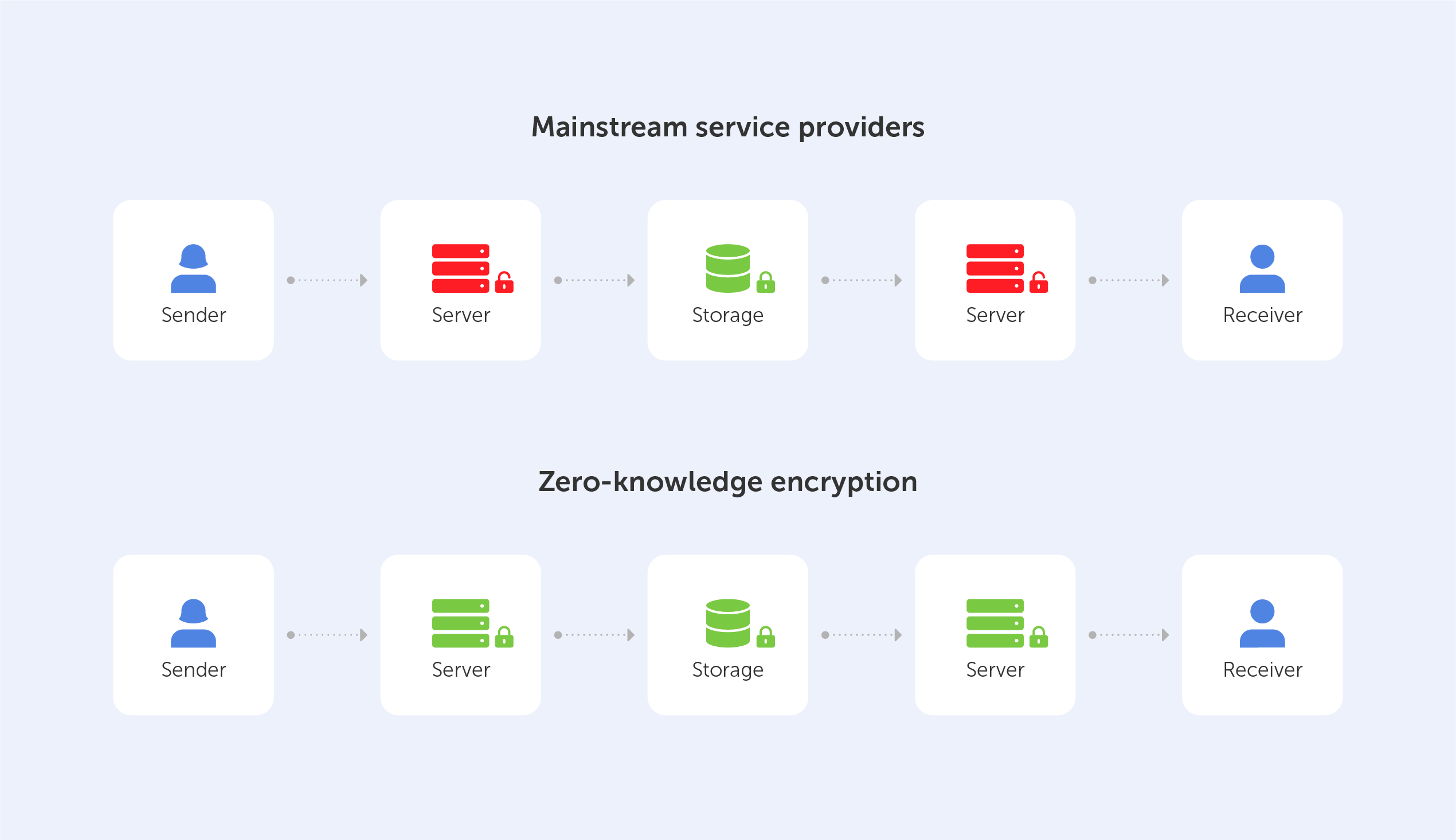
In order to gain a better understanding of the factors that led to the development of Zero-Knowledge Encryption, we've decided to present a succinct, yet comprehensive, assessment of the advantages and disadvantages of three existing options:
Encryption-in-transit
Data in-transit, also known as data in motion, is data that is actively flowing from one point to another, such as that over the internet or over a private network. Data protection in transit refers to the security of data while it is being transferred from one network to another or from a local storage device to a cloud storage device. Effective data protection measures for in-transit data are critical because data is often considered less secure while in transit. Think of it like hiring security guards to accompany your cash-in-transit vehicle’s trip to the bank.
This means that, while using this approach, stored docs are 100% decryptable, so vulnerable.
As for our everyday life, the following technologies use the ‘encryption-in-transit’ approach:
- Transport Layer Security (TLS), which is aimed at ensuring your security on the web;
- Secure/Multipurpose Internet Mail Extensions (S/MIME), which are often used for email message security.

Encryption-at-rest
Any data encryption is the process of converting one type of data into another that cannot be decrypted by unauthorized users. For example, you may have saved a copy of your passport. You obviously don't want this data to be easily accessed. If you store encrypted data on your server, it’s effectively "resting" there (which is why it’s called encryption-at-rest). This is usually accomplished by the use of an algorithm that is incomprehensible to a user who does not have access to the encryption key needed to decode it. Only an authorized person will be able to access the file, ensuring that your data is kept safe.
The Advanced Encryption Standard (AES) is often used to encrypt data at rest.
But, in order to access the data, you need a key — and that’s where the potential vulnerability lies.

Encryption-at-rest is like storing your data in a secret vault, encryption-in-transit is like putting it in an armored vehicle with security guards for transport.
End-to-end encryption
End-to-end encryption is the act of applying encryption to messages on one device so that only the device to which it is sent can decrypt it. The message travels all the way from the sender to the recipient in encrypted form.
In practice, it means that only the communicating users (who have the key) can read the messages.
End-to-end encryption has created an impregnable fortress for communication services (for example, messengers), going beyond the security "façade" of encryption-in-transit and encryption-at-rest solutions.
This is the most common approach when protecting oneself against data breaches nowadays, but it only works from "one end to the other," as the term implies. Even though this all sounds great, end-to-end encryption can only be used for a "communication system" like Whatsapp or Telegram.

While theoretically sound, end-to-end encryption lacks flexibility, so it can’t be used when the "two ends" that share data don't exist, such as for cloud storage.
This is the motivation behind the development of Zero-Knowledge Encryption, a method that solves the problem by hiding the encryption key, even from the storage provider, resulting in an authentication request without the need for password exchange.
Zero-Knowledge encryption
To log in to an account, you usually have to type in the exact password. In today's hyperconnected world, it's normal practice to tell the server your secret key ahead of time and test whether it matches.
Instead, there is another, more secure way, to manage this delicate process and that’s called Zero-Knowledge Encryption.
Without diving deep, The Zero-Knowledge relies on three main requirements:
- Completeness — an honest prover will be able to convince the verifier that he has the password by completing some process in the required way;
- Soundness — the verifier will almost certainly discover when the prover is lying;
- Zero-knowledge — if the prover has a password, the verifier receives no more information other than the fact that the statement is true.
Essentially, the system will check to see if you can demonstrate your knowledge several times by responding to various conditions. It’s like a brute force attack carried out backwards — you perform the same action many times in order to make sure that the prover isn’t lying.
Instead of concluding, let’s round up the pros and cons of Zero-Knowledge proof encryption when compared to the alternatives:

The con here is a clear example of the exceptional security provided by the Zero-Knowledge Encryption solution, which prevents even system administrators from recovering your password. This is why we, at Passwork, rely on this technology in our products. Ultimately, that’s why you can rely on us too.
Comprehensive guide: Cybersecurity vocabulary – terms and phrases you need to know
Cybersecurity — as complex as it sounds — is an essential concept that we all need to be aware of in this day and age. Computers, phones, and smart devices have become an extension of our bodies at this point, which makes their security paramount. From your family photos to your bank

Why Zero-Knowledge Encryption is the best
In this year of our lord, 2022, the term ‘Zero-Knowledge Encryption’ equates to best-in-class data insurance. We’ve already written an article named “What is Zero-Knowledge Proof?”, so we’re not going to look at definitions here, but rather, we’re going to explore the pros and cons of Zero-Knowledge
Python connector 0.1.5: Automated secrets management
The new Python connector version 0.1.5 expands CLI utility capabilities. We’ve added commands that solve critical tasks for DevOps engineers and developers — secure retrieval and updating of secrets in automated pipelines. What this solves Hardcoded secrets, API keys, tokens, and database credentials create security vulnerabilities and operational bottlenecks.

Why Zero-Knowledge Encryption is the best
Many times, we’ve mentioned self-signed certificates and their most common use cases in our blog. After all, the main difference between a regular certificate and a self-signed one is that in the latter case, you act as the CA (Certificate Authority). But there are a variety of services that provide CA services for free, with the most popular being ‘Let’s Encrypt’, which is going to be the subject of this article.
What’s that?
‘Let’s Encrypt’ is a free certificate authority developed by the Internet Security Research Group (ISRG).
It provides free TLS/SSL certificates to any suitable client via the ACME (Automatic Certificate Management Environment) protocol. You can use these certificates to encrypt communication between your web server and your users. ‘Let's Encrypt’ provides two types of certificates. Single-domain SSL and Wildcard SSL, which covers a single domain and all of its subdomains. Both types of SSL certificates have a 90-day validity period. These domain-validated certificates do not require a dedicated IP address. They accomplish this by delivering the client a unique token and then retrieving a key generated from that token via an HTTP or DNS request.
There are dozens of clients available which can be easily integrated with a variety of standard administrative tools, services, and servers. They also come written in a range of different computer languages.
We'll use the win-acme client in this tutorial because it's a basic, open-source, and constantly updated command-line application. It not only produces certificates but also automatically installs and renews them. And yes, this tutorial is for Windows users.
How does it work?
‘Let's Encrypt’ verifies the ownership of your domain before issuing a certificate. On your server, the Let's Encrypt client creates a temporary file (a token) with the required information. The Let's Encrypt validation server then sends an HTTP request to get the file and validates the token, ensuring that your domain's DNS record resolves to the ‘Let's Encrypt’ client-server.
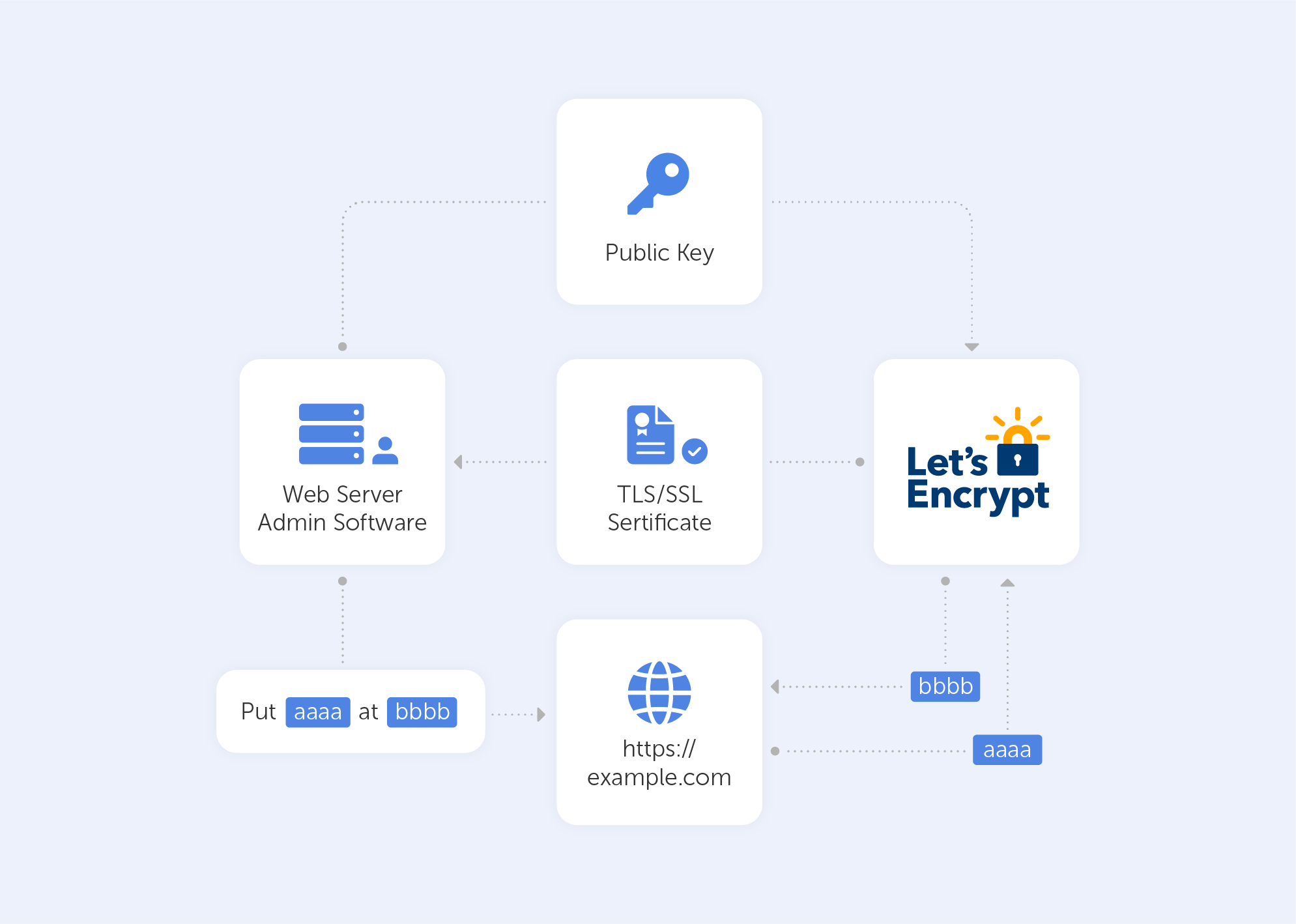
In an HTTP-based challenge, for example, the client will generate a key from a unique token and an account token, then save the results in a file that the web server will serve. The file is then retrieved from the Let's Encrypt servers at: http://passwork.com/.well-known/acme-challenge/token.
The client has demonstrated that it can control resources on example.com if the key is correct, and the server will sign and provide a certificate.
How do I set it up?
Before we start:
- Make sure that you’ve downloaded the latest version of the application on the server from its Github release page;
- Scroll down to ‘assets’ and download the zip package named win-acme.v2.x.x.x.zip from the release page. If you're having difficulty with Internet Explorer, you may install Chrome on the server following this approach. Once the application has been downloaded, unpack it and save it somewhere safe for future use.
Now let’s Generate the Let’s Encrypt Certificates
Simply run wacs.exe to generate the Let's Encrypt certificates. Because we downloaded the application via the internet, you may receive a notification from Windows Defender claiming that "Windows protected your PC". Because of this, after clicking the "More Info" link, click the "Run Anyway" option. Because it’s open-source and widely utilized, the application is completely safe to use.
Follow these simple steps once the application has started:
- Choose N in the main menu to create a new certificate with default settings;
- Choose how you want to determine the domain name(s) that you want to include in the certificate. These may be derived from the bindings of an IIS site, or you can input them manually;
- A registration is created with the ACME server if no existing one can be found. You will be asked to agree to its terms of service and to provide an email address that the administrators can use to contact you;
- The program negotiates with the ACME server to try and prove your ownership of the domain(s) that you want to create the certificate for. By default, the http validation mode is picked and handled by our self-hosting plugin. Getting validation right is often the most tricky part of getting an ACME certificate. If there are problems, please check out some of the common issues for an answer;
- After the proof has been provided, the program gets the new certificate from the ACME server and updates or creates IIS bindings as required, according to the logic documented here;
- The program remembers all choices that you made while creating the certificate and applies them for each subsequent renewal.
For advanced instructions, visit this page.
And that’s pretty much it. It will successfully generate an SSL certificate for you if your domain is pointing to your server. It will also include a scheduled task that will renew the certificate when it expires. The SSL certificate will be installed automatically by the application.
Are there other options?
‘Certbot’ is the most widely used kind of ‘Let's Encrypt’ client. We didn’t give it much light in this article because it's “designed for Linux” and also a little more advanced. It comes with easy-to-use automatic configuration features for Apache and Nginx. And yes, there is a Windows version as well.
There are many other clients to choose from – the ACME protocol is open and well-documented. On their website, ‘Let's Encrypt’ keeps track of all ACME clients.
Here’s a list of the best options (n.b. most are for Linux):
- lego. Lego is a one-file binary installation written in Go that supports many DNS providers;
- acme.sh. Acme.sh is a simple shell script that can run in non-privileged mode and interact with more than 30 different DNS providers;
- Caddy. Caddy is a full web server written in Go with built-in support for Let’s Encrypt.
‘Let’s Encrypt’ is just great, there are no other ways to put it. It’s a free, automated, and open certificate authority, run for the public’s benefit. It can be accessed via a variety of tools and services. The best part is, they really keep their motto close to heart:
“We give people the digital certificates they need in order to enable HTTPS (SSL/TLS) for websites, for free, in the most user-friendly way we can. We do this because we want to create a more secure and privacy-respecting Web for all.”
Insider threats: Prevention vs. privacy
Insider threats are a major cybersecurity risk, often overlooked. Prevention requires balancing trust and security focus on monitoring risk-based behaviors, not constant surveillance. Use AI for early detection, educate staff, and be transparent to foster trust while protecting data.

5 ways to keep your business safe from cyber threats
In an era where cybercrime is rampant, businesses must take a proactive approach to safeguard their confidential information. In 2021 alone, over 118 million people have been affected by data breaches, and this number is expected to rise exponentially. In this post, we’ll discuss some of the best practices

The 2025 small business cybersecurity checklist: A complete guide | Passwork
Passwork’s 2025 cybersecurity checklist, based on the NIST framework, provides actionable steps to prevent data breaches and financial loss.

An Overview of ‘Let's Encrypt’
It is rare for technologies to be born from ambitious philosophical concepts or mind games. But, when it comes to security and cryptography – everything is a riddle.
One of such riddles is ‘How can you prove that you know a secret without giving it away?’. Or in other words, ‘how can you tell someone you love them without saying that you love them?’.
The Zero-Knowledge Proof technique, as suggested by the name, uses cryptographic algorithms to allow several parties to verify the authenticity of a piece of information without having to share the material that makes it up. But how is it possible to prove something without supporting evidence? In this article, we’ll try our best to break it down for you as easily as possible.
Why?
We’re asking ourselves day after day – why on Earth would people decide to use such a complicated concept. Well, millions of people use the internet every day, accepting cookies and sharing personal information in exchange for access to services and digital products. Users are gradually becoming more vulnerable to security breaches and unauthorized access to their data. Furthermore, individuals frequently have to give up their privacy in return for digital platform services such as suggestions, consultations, tailored support, and so on, all of which wouldn’t be available when browsing privately. Due to all the above mentioned, there is a certain asymmetry regarding access to information – you give your information in exchange for a service.
In 1985, three great minds noticed ‘a great disturbance in the Force’ ahead of their time and released a paper called "The Knowledge Complexity of Interactive Proof-Systems" which introduced the concept of Zero-Knowledge Proof (ZKP) for the first time.
So what is it?
ZKP is a set of tools that allows an item of data to be evaluated without having to reveal the data that supports it. This is made feasible by a set of cryptographic methods that allow a "tester" to mathematically prove to a "verifier" that a computational statement is valid without disclosing any data.
It is possible to establish that particular facts are correct without having to share them with a third party in this way. For example, a user could demonstrate that he is of legal age to access a product or service without having to reveal his exact age. Or, it’s a bit like showing your friend your driving license instead of proving to him that you can drive by road-tripping to Mexico.
This technique is often used in the digital world to authenticate systems without the risk of information being stolen. Indeed, it’s no longer necessary to provide any personal data in order to establish a person's identity.
Sounds great, but how does it work?
The prover and the verifier are the two most important roles in zero-knowledge proofs. The prover must demonstrate that they are aware of the secret whereas the verifier must be able to determine whether or not the prover is lying.
It works because the verifier asks the prover to do actions that can only be done if the prover is certain that he or she is aware of the secret. If the prover is guessing, the verifier's tests will catch him or her out. If the secret is known, the prover will pass the verifier's exam with flying colors every time. It's similar to when a bank or other institution requests letters from a known secret word in order to authenticate your identity. You're not telling the bank how much money you have in your account; you're simply demonstrating that you know.
Wonderful, but how does it REALLY work?
To answer this, let’s take a look at a piece of research by Kamil Kulesza.
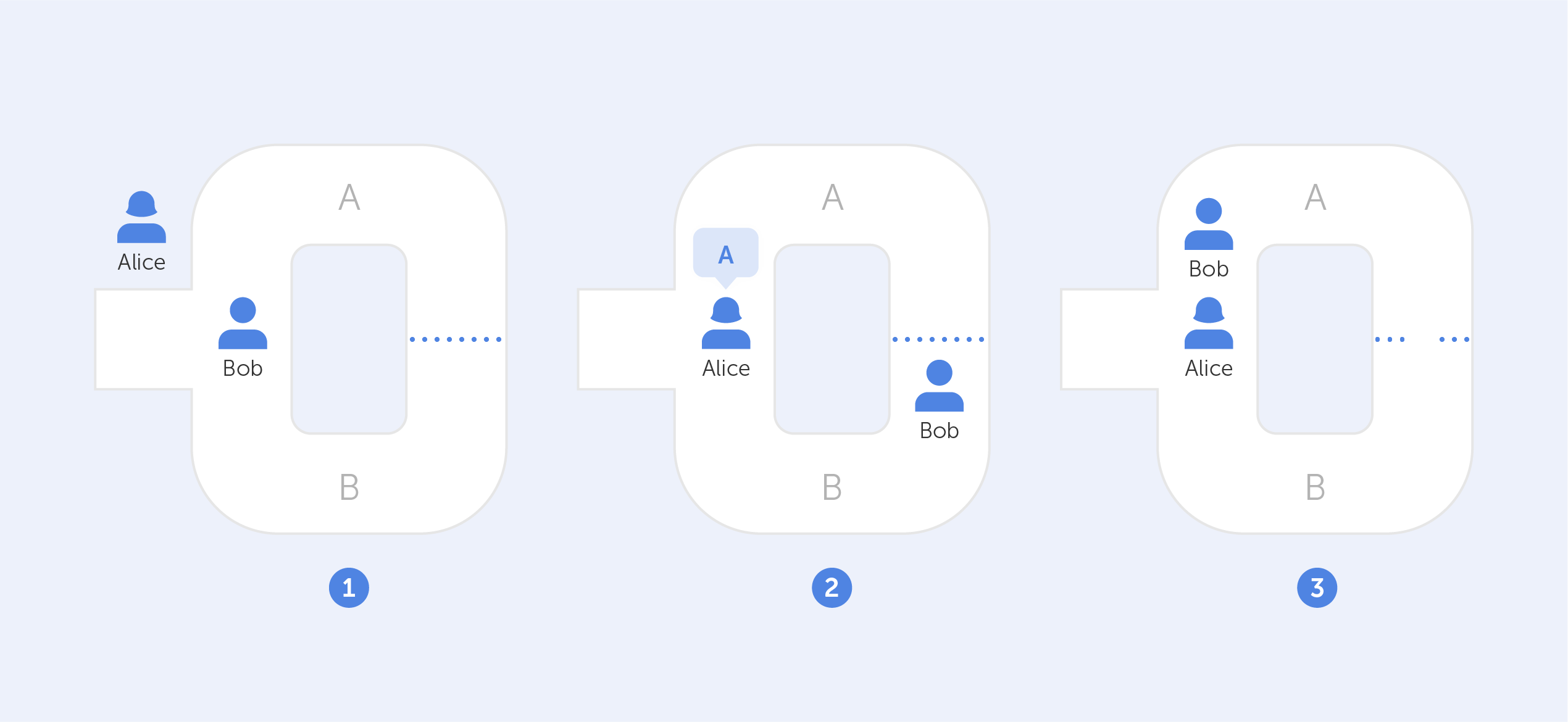
Assume that two characters, Alice and Bob, find themselves at the mouth of a cave with two independent entrances leading to two different paths (A and B). A door inside the cave connects both paths, but it can only be unlocked with a secret code. This code belongs to Bob (the 'tester,') and Alice (the 'verifier,') wants to buy it, but first, she wants to make sure Bob isn't lying.
How can Bob demonstrate to Alice that he has the code without divulging its contents? They perform the following to achieve this: Bob enters the cave via one of the entrances at random while Alice waits outside (A or B). Once inside, Alice approaches the front door, summons Bob, and instructs him to use one of the two exits. Bob will always be able to return by the path that Alice used since he knows the secret code.
Bob will always be able to return via the path that Alice directs him to, even if it does not coincide with the one he chose in the first place, because he can unlock the door and depart through the other side with the secret code.
But wait a minute, there is still a 50% chance that both Alice and Bob chose the same path, right? It is correct indeed, however, if this exercise is repeated several times, the likelihood that Bob will escape along the same path chosen by Alice without possessing the code decreases until it is almost impossible. Conclusion? If Bob leaves this path a sufficient number of times, he has unmistakably shown to Alice that his claim of holding the secret code is true. Moreover, there was no need to reveal the actual code in this case.
You can find out more about the Bob and Alice metaphor here.
Got it, so how is it used?
As for right now, ZKP is developing hand in hand with blockchain technology.
Zcash is a crypto platform that uses a unique iteration of zero-knowledge proofs (called zk-SNARKs). It allows native transactions to stay entirely encrypted while still being confirmed under the network's consensus rules. It’s a great example of this technology being used in practice.
Even though zero-knowledge proofs have a lot of potential to change the way today's data systems verify information, the technology is still considered to be in its infancy — primarily because researchers are still figuring out how to best use this concept while identifying any potential flaws. This, however, doesn’t stop us from using this protocol in our products! ;)
For a deeper understanding of the technical aspects and history behind this protocol, we recommend watching this video on YouTube.
Python connector 0.1.5: Automated secrets management
The new Python connector version 0.1.5 expands CLI utility capabilities. We’ve added commands that solve critical tasks for DevOps engineers and developers — secure retrieval and updating of secrets in automated pipelines. What this solves Hardcoded secrets, API keys, tokens, and database credentials create security vulnerabilities and operational bottlenecks.

Why Zero-Knowledge Encryption is the best
In this year of our lord, 2022, the term ‘Zero-Knowledge Encryption’ equates to best-in-class data insurance. We’ve already written an article named “What is Zero-Knowledge Proof?”, so we’re not going to look at definitions here, but rather, we’re going to explore the pros and cons of Zero-Knowledge
How to create a secure password
Of course you want to keep your data safe. So why are so many security precautions frequently overlooked? Many accounts, for example, are protected by weak passwords, making it easy for hackers to do their work. There is a fine line between selecting a password that no one can guess

What is Zero-knowledge proof?
Cryptography is both beautiful and terrifying. Perhaps a bit like your ex-wife. Despite this, it represents a vital component of day-to-day internet security; without it, our secrets kept in the digital world would be exposed to everyone, even your employer. I doubt you’d want information regarding your sexual preferences to be displayed to the regional sales manager while at an interview with Goldman Sachs, right?
Computers are designed to do exactly what we ask them to do. But sometimes there are certain things that we don’t want them to do, like expose your data through some kind of backdoor. This is where cryptography comes into play. It transforms useful data into something that can’t be understood without the proper credentials.
Let’s take a look at an example. Most internet services need to store their users’ password data on their own servers. But they can’t store the exact values that people input on their devices because, in the event of a data breach, malevolent intruders would effectively gain access to a simple spreadsheet of all usernames and passwords.
This is where ‘Hash’ and ‘Salt’ help us a lot. Throughout this article, we’re going to explain these two important encryption concepts through simple functions in Node.JS.
What is a ‘hash’?
A ‘hash’ literally means something that has been chopped and mixed, and originally was used to describe a kind of food. Now, chopping and mixing are exactly what the hash function does! You start with some data, you pass it through a hash function where it gets whisked and chopped, and then you watch it get transformed into a fixed-length value (which at first sight seems pretty meaningless). The important nuance here is that, contrary to cooking, an input always produces a corresponding output. For the purposes of cryptography, such a hash function should be easily computable and all values should be unique. It should work in a similar way to mashing potatoes – mashing is a one-way process; the raw potato may not be restored once it has been mashed. Indeed, the result of a hash function should be impenetrable to computer-led reverse engineering efforts.
These properties come in handy when you’re looking to store user passwords on a database – you don’t want anyone to know their real values.
Let’s implement a hash in Node.JS!
First, let’s import the createHash function from the built-in ‘crypto’ module:
const { createHash } = require ('crypto');Next, we ought to define the module that we’re naming as the ‘hash’ (which takes a string as the input, and returns a hash as the output):
function hash(input) {
return createHash();
}We also need to specify the hashing algorithm that we want to use. In our case, it will be SHA256. SHA stands for Secure Hash Algorithm and it returns a 256-bit digest (output). It is important to architect your code so it is easy to switch between algorithms because at some point in time they won’t be secure anymore. Remember, cryptography is always evolving.
function hash(input) {
return createHash('sha256');
}Once we call our hashing function, we may call ‘update’ with the input value and return the output by calling ‘digest’. We should also specify the format of the output (e.g. hex). In our case, we’ll go with Base64.
function hash(input) {
return createHash('sha256').update(input).digest('base64');
}Now that we have our hash function, we can provide some input, and console log the result.
let youShallNotPassPass = 'admin1234';
const hashRes1 = hash(youShallNotPassPass);
console.log(hashRes1)Here’s our baby hash:
rJaJ4ickJwheNbnT4+I+2IyzQ0gotDuG/AWWytTG4nA=
So, how can we use this long, convoluted string of numbers, letters, and symbols? Well, now it’s easy to compare two values while operating with only hashes.
let youShallNotPassPass = 'admin1234';
const hashRes1 = hash(youShallNotPassPass);
const hashRes2 = hash(youShallNotPassPass);
const isThereMatch = hashRes1 === hashRes2;
console.log(isThereMatch ? 'hashes match' : 'hashes do not match’)As long as hash values are unique object representations, they can be useful for object identification. For example, they might be used to iterate through objects in an array or find a specific one in the database.
But we have a problem. Hash functions are very predictable. On top of that, people don’t use strong passwords that often, so the hacker may just compare the hashes on a database with a precomputed spreadsheet of the most common passwords. If the values match – the password is compromised.
Because of this, it’s insufficient to just use a hash function to store unique ids on a password database.
And that’s where our second topic makes an entrance – Salt.
‘Salt’ is a bit like the mineral salt that you would add to a batch of mashed potatoes – the taste will definitely depend on the amount and type of salt used. This is exactly what salt in cryptography is – random data that is used as an additional input to a hash function. Its use makes it much harder to guess what exact data stands behind a certain hash.
So, let’s salt our hash function!
First, we ought to import ‘Scrypt' and ‘RandomBytes’ from the ‘crypto’ module:
const { scryptSync, randomBytes } = require('crypto');Next, let’s implement signup and login functions that take ‘nickname’ and ‘password’ as their inputs:
function signup(nickname, password) { }
function login(nickname, password) { }When the user signs up, we will generate a salt, which is a random Base64 string:
const salt = randomBytes(16).toString('base64');And now, we hash the password with a 'pinch' of salt and a key length, which is usually 64:
const hashedPassword = scryptSync(password, salt, 64).toString('base64');We use ‘Scrypt’ because it’s designed to be expensive computationally and memory-wise in order to make brute-force attacks unrewarding. It’s also used as proof of work in cryptocurrency mining.
Now that we have hashed the password, we need to store the accompanying salt in our database. We can do this by appending it to the hashed password with a semicolon as a separator:
const user = { nickname, password: salt + ':' + hashedPassword}Here’s our final signup function:
function signup(nickname, password) {
const salt = randomBytes(16).toString('base64');
const hashedPassword = scryptSync(password, salt, 64).toString('base64');
const user = { nickname, password: salt + ':' + hashedPassword};
users.push(user);
return user;
}Now let’s create our login function. When the user wants to log in, we can grab the salt from our database to recreate the original hash:
const user = users.find(v => v.nickname === nickname);
const [salt, key] = user.password.split(':');
const hash = scryptSync(password, salt, 64);After that, we simply check whether the result matches the hash in our database. If it does, the login is successful:
const match = hash === key;
return match;Here is the complete login function:
function login(nickname, password) {
const user = users.find(v => v.nickname === nickname);
const [salt, key] = user.password.split(':');
const hash = scryptSync(password, salt, 64).toString('base64');
const match = hash === key;
return match;
}Let’s do some testing:
//We register the user:
const user = signup('Amy', '1234');
//We try to login with the wrong pass:
let isSuccess = login('Amy', '12345');
console.log(isSuccess ? 'Login success' : 'Wrong password!')
//Wrong password!
//We try to login with the correct pass:
isSuccess = login('Amy', '1234')
console.log(isSuccess ? 'Login success' : 'Wrong password!')
//Login successOur example, hopefully, has provided you with a very simplified explanation of the signup and login process. It’s important to note that our code is not protected against timing attacks and it doesn’t use PKI infrastructure to check hashes, so there are plenty of vulnerabilities for hackers to exploit.
Cryptography itself can be described as the constant war between hackers and cryptographic engineers. Or, that familiar legal battle with your ex-wife over her maintenance payments. After all, what works today may not work tomorrow. A proof of MD5 hash algorithm vulnerability is a very good example.
So if your task is to ensure your users’ data privacy, be ready to constantly update your functions to counteract the recent ‘breakthroughs’.
Python connector 0.1.5: Automated secrets management
The new Python connector version 0.1.5 expands CLI utility capabilities. We’ve added commands that solve critical tasks for DevOps engineers and developers — secure retrieval and updating of secrets in automated pipelines. What this solves Hardcoded secrets, API keys, tokens, and database credentials create security vulnerabilities and operational bottlenecks.

How secure are smart home devices?
Are you sure that your home is protected in the way that you think? Sure, you can secure it with modern locks or an alarm system to protect yourself from robbers who want to steal your money or furniture, but what about those who are looking at your home as
Insider threats: Prevention vs. privacy
Insider threats are a major cybersecurity risk, often overlooked. Prevention requires balancing trust and security focus on monitoring risk-based behaviors, not constant surveillance. Use AI for early detection, educate staff, and be transparent to foster trust while protecting data.

What is password hashing and salting?
Introduction
Let's imagine that you decided to google ‘best sauces for Wagyu steak’. You went through several web pages, and then on page two of the search results, you get this notification from your Chrome browser:
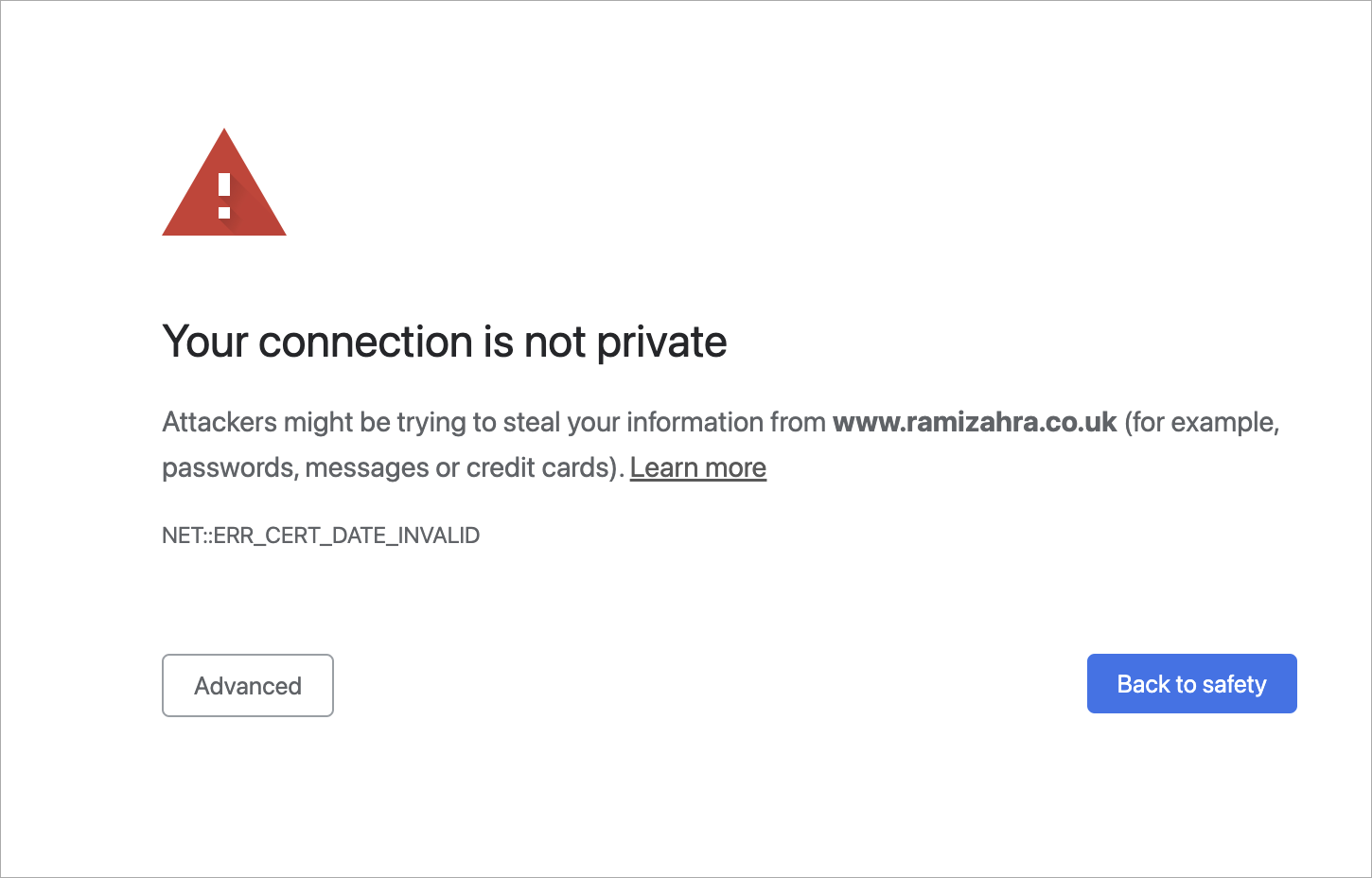
Something went wrong, that's for sure. What happened? Should you proceed to the page without a private connection?
An IT expert would surely reply:
The error that you got here was probably because of an SSL/TLS handshake failure.
SSL? TLS?? Acronyms you’ve no doubt heard before, but ones that nevertheless evoke a dreary sense of confusion in the untrained mind. In this article, we’ll try to explain what SSL/TLS is, how it works and at the very least, you’ll understand what that lock icon on the address bar is.
Where did TLS originate?
TLS stands for Transport Layer Security, and it is right now the most common kind of Web PKI. It’s used not only to encrypt internet browsing but also for end-to-end connection (video calling, messaging, gaming, etc.).
As for now, we expect almost any kind of connection on the internet to be encrypted, and if something is encrypted, we get an alert similar to that seen in figure A. But that wasn't always the case. If you go back to the mid-90s – very little on the internet was encrypted. Maybe that was because fewer people were using the internet back then, or maybe it was because there weren’t credit-card details flying all over the place.
The history of TLS starts with Netscape. In 1994, it developed Secure Socket Layer 1 – the grandfather of modern TLS. Technically, it fits between TCP and HTTP as a security layer. While version 1 was used only internally and was full of bugs, very quickly, they fixed all the issues and released SSL 2. Then, Netscape patented it in 1995 with a view to stopping other people patenting it so they could release it for free. This was a very odd yet generous move, considering what the real-life patent practice was at that time.
In 1995, the world was introduced to Internet Explorer, a browser that used a rival technology called PCT (Private Communications Technology), which was very similar to SSL. But as with any rivalry – there could only be one winner. In November 1996, SSL 3 was released, which, of course, was an improvement on SSL 2. Right after that, the Internet Engineering Task Force created the Transport Layer Security Working Group to decide what the new standard for internet encryption would be. It was subsequently renamed from SSL to TLS (as far as we know, this was because Microsoft didn't want Netscape to have dibs on the name). It actually took three years for the group to release TLS 1. It was so similar to SSL 3 that people began to name it SSL 3.1. But over time, through updates, the security level rose massively; bugs were terminated, ciphers were improved, protocols were updated etc.
How does TLS actually work?
TLS is a PKI protocol that exists between two parties. They effectively have to agree on certain things to identify each other as trustworthy. This process of identification is called a 'handshake'.
Let’s take a look at a TLS 1.2 handshake, as an example.
First, let's load any webpage, then, depending on your browser, press the lock icon near the web address text field. You’ll be shown certificate info and somewhere between the lines you'll find a string like this:
This is called a Cipher Suite. It’s a string-like representation of our 'handshake' recipe.
So, let’s go through some of the things shown here:
- First, we have ECDHE (Elliptic-curve Diffie–Hellman), which is a key agreement protocol that allows two parties, each having an elliptic-curve public–private key pair, to establish a shared secret over an insecure channel. In layman’s terms, this is known as key exchange;
- The RSA is our Public Key authentication mechanism (remember, we need a Public Key for any PKI);
- AES256 refers to the cipher that we’re going to use (AES) and its' key size (256);
- Lastly, SHA384 is effectively a building block that is used to perform hash functions.
Now, the trick is to exchange all that data in just several messages via our 'handshake'.
What exactly happens when we go to a new web page?
After we establish a TCP (Transmission Control Protocol) connection, we start our handshake. As always on the web, the user (Client) is requesting data from the Server – so he sends a 'Client Hello' message, which contains a bunch of data including:
- The max TLS version that this Client can support so that both parties are able to 'speak the same language;
- A random number to protect from replay attacks;
- List of the cipher suites that the Client supports.
Assuming the Server is live, it responds with 'Server Hello', containing the Cipher Suite and TLS version it chose to connect with the Client + a random number. If the server can't choose a Suite or TLS version due to version incompatibility – it sends back a TLS Alert with a handshake failure. At this point, both the User and the Server know the communication protocol.
Keep in mind that the server is sending a Public key and a Certificate containing an RSA key. It’s important to know that the Certificate has an expiration date. You’ll understand why by the end of the article.
On top of that, the Server is sending a Server Key Exchange Message containing parameters for ECDHE with a public value. Very importantly, this Exchange Message also contains a digital signature (all previous messages are summarized using a hash function and signed using the private key of the Server). This signature is crucial because it provides proof that the Server is who they say they are.
When the Server is done transmitting all the above-mentioned messages, it sends a 'Server Hello Done' message. In Layman’s terms, that’s an ‘I’m done for the day, I’ll see you at the pub’ kind of message.
The Client, on the other hand, will look at the Certificate and verify it. After that, it will verify the signature using the Certificate (you can't have one without the other). If all goes well, the Client is assured of the Server’s authenticity and sends a Client Key Exchange Message. This message doesn't contain a Certificate but does contain a Premaster Secret. It is then combined with the random numbers that were generated during the ‘Hello’ messages to produce a Master Secret. The Master Secret is going to be used for encryption at the next step.
It may seem very complicated now, but we’re almost done!
The next stage involves the Client sending the ‘Change Cipher Spec’ message, which basically says "I’ve got everything, so I can begin encryption – the next message I'll send you is going to be encrypted with parameters and keys".
After that, the Client proceeds to send the ‘Finished’ message containing a summary of all the messages so far encrypted. This helps to ensure that nobody fiddled with the messages; if the Server can't decrypt the message, it leaves the 'conversation'.
The Server will reply in the same way – with a Change Cipher Spec and a Finished message.
Handshaking is now done, parties can exchange HTTP requests/responses and load data. By the way, the only difference between HTTP and HTTPS is that the last one is secure – that's what the 'S' stands for there.
As you can see, it's incredibly difficult to crack this system open. However, that's exactly what we need to ensure security. Moreover, those two round trips that the data travels take no time at all, which is great; nobody wants their GitHub to take a month and a half to load up. By the way, the more advanced TLS 1.3 does all that in just one round trip!
Your connection is not private
When something goes wrong with TLS, you’ll see the warning that we demonstrated at the very beginning of this article. Usually, those are issues associated with the Certificate and its expiration date. That’s why your internet will refuse to work if you’ve messed around with the time and date settings on your device. But, if everything with the date and time is in check – never proceed to a website that triggers this warning, because most likely, between you and the server, somebody is parsing your private data.
The 2025 small business cybersecurity checklist: A complete guide | Passwork
Passwork’s 2025 cybersecurity checklist, based on the NIST framework, provides actionable steps to prevent data breaches and financial loss.

Passwork 7: Security verified by HackerOne
Passwork has successfully completed the penetration testing, carried out by HackerOne — the world’s largest platform for coordinating bug bounty programs and security assessments. This independent evaluation confirmed Passwork’s highest level of data protection and strong resilience against modern cyber threats. What the pentest covered Security architecture and data

Python connector 0.1.5: Automated secrets management
The new Python connector version 0.1.5 expands CLI utility capabilities. We’ve added commands that solve critical tasks for DevOps engineers and developers — secure retrieval and updating of secrets in automated pipelines. What this solves Hardcoded secrets, API keys, tokens, and database credentials create security vulnerabilities and operational bottlenecks.

What is Transport Layer Security (TLS) & how does it work?
Let’s imagine that somehow you’re in the driver’s seat of a start-up, and a successful one too. You’ve successfully passed several investment rounds and you’re well on your way to success. Now, big resources lead to big data and with big data, there’s a lot of responsibility. Managing data in such a company is a struggle, especially considering that data is usually structured in an access hierarchy – Excel tables and Google Docs just don’t cut the cake anymore. Instead, the company yearns for a protocol well equipped to manage data. The company yearns for LDAP.
What is LDAP?
The story of LDAP starts at the University of Michigan in the early 1990s when a graduate student, Tim Howes, was tasked with creating a campus-wide directory using the X.500 computer networking standard. Unfortunately, accessing X.500 records was impossible without a dedicated server. Additionally, there was no such thing as a ‘client app’. As a result, Howes co-created DIXIE, a directory client for X.500. This work set the foundations for LDAP, a standards-based version of DIXIE for both clients and servers – an acronym for the Lightweight Directory Access Protocol.
It was designed to maintain a data hierarchy for small bits of information. Unlike ‘Finder’ on your Mac, or ‘Windows Explorer’ on your PC, the ‘files’ inside the directory tree, although small, are contained in a very hierarchical order – exactly what you need to organize, for example, your HR structure, or when accessing a file. Compared to good old Excel, it is not a program, but rather a protocol. Essentially, a set of tools that allow users to find the information that they need very quickly.
Importantly, this protocol answers three key questions regarding data management:
— Who? Users must authenticate themselves in order to access directories.
— How? A special language is used that provides for query or data manipulations.
— Where? Data is stored and organized in a proper manner.
Let’s now go through these key questions in greater detail.
Who?
It’s bad taste to provide internal data to any old Joe. That’s why LDAP users cannot access information without first proving their identity.
LDAP authentication involves verifying provided usernames and passwords by connecting with a directory service that uses the LDAP protocol. All this data is stored in what is referred to as a core user. This is a lot like logging into Facebook, where you’re only able to access a user’s feed and photos if they’ve accepted your friend request, or if their profile has been set to public.
Some companies that require advanced security use a Simple Authentication and Security Layer (SASL), for example, Kerberos, for the authentication process.
In addition, to ensure the maximum safety of LDAP messages, as soon as data is accessed via devices outside the company’s walls, Transport Layer Security (TLS) may be used.
How?
The main task of a data management system is to provide “many things to many users”.
Rather than creating a complex system for each type of information service, LDAP provides a handful of common APIs (LDAP commands) to do this. Supporting applications, of course, have to be written to use these APIs properly. Still, the LDAP provides the basic service of locating information and can thus be used to store information for other system services, such as DNS, DHCP, etc.
Basic LDAP commands
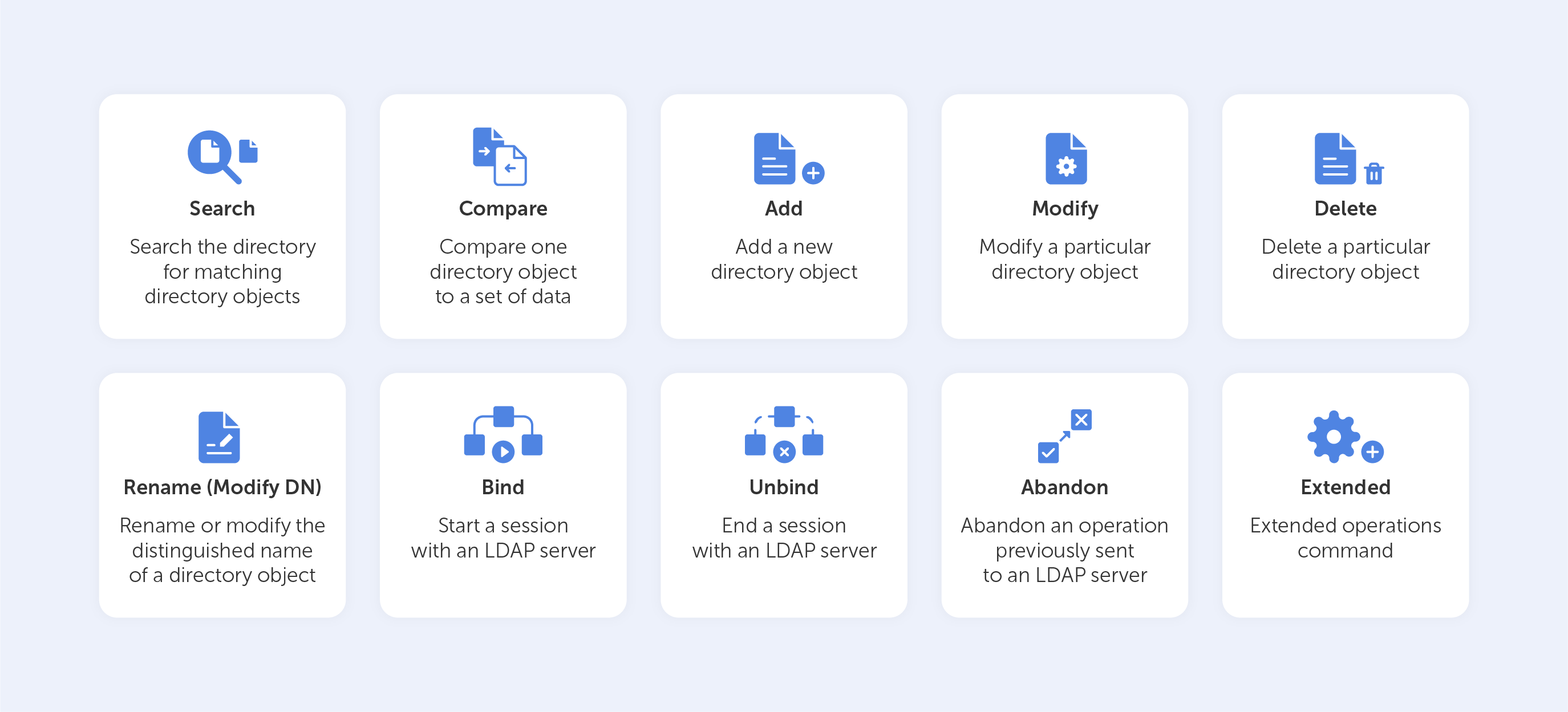
Let’s look at the ‘Search’ LDAP command as an example, if you’d like to know which group a particular user is a part of, you might need to input something like this:
(&(objectClass=user)(sAMAccountName=BradleyC)
(memberof=CN=Perohouse,OU=Users,DC=perohouse,DC=com))
Isn’t it beautiful? Not quite as simple as performing a Google search, that’s for sure. So, your employees will perform all their directory services tasks through a point-and-click management interface like Varonis DatAdvantage.
All those interfaces may vary depending on their configuration, which is why new employees should be trained to use them, even if they’ve used LDAP before.
Where?
As we mentioned before, LDAP has the structure of a tree of information. Starting with the roots, it contains hierarchical nodes relating to a variety of data, by which the query may then be answered.
The root node of the tree doesn't really exist and can't be accessed directly. There is a special entry called the root directory specific entry, or rootDSE, that contains a description of the whole tree, its layout, and its contents. But, this really isn't the root of the tree itself. Each entry contains a set of properties, or attributes, in which data values are stored.
The tree itself is called the directory information tree (DIT). Branches of this tree contain all the data on the LDAP server. Every branch leads to a leaf in the end – a data entry, or directory service entry (DSE). These entries contain actual records that describe objects such as users, computers, settings, etc.
For example, such a tree for your company could start with the description of a position held, starting with you at the top as the director, finishing at the bottom with Joe Bloggs, the intern.
Each position would be tied to a person with a set of attributes, complete with links to subordinates. The attributes for a person may include their name, surname, phone number, email, in addition to their responsibilities. Each attribute would have a value inside, like ‘Joe’ for name and ‘Bloggs’ for surname.
The actual data contents may vary, as they totally depend on use. For example, you could have data issuing rights to certain people regarding the coffee machine. So, no Frappuccino for our intern Joe.
Sure, you can add more sophisticated data regarding each individual – their personal family trees, or even voice samples for instance, but typically, the LDAP would just point to the place where such data can be found.
Is it worth it?
LDAP is able to aggregate information from different sources, making it easier for an enterprise to manage information. But as with any type of data organization, the biggest difficulty is creating a proper design for your tree. There is always trial and error involved while building a directory for a specific corporate structure. Sometimes this process is so difficult that it even results in the reorganization of the company itself in favor of the hierarchical model. Despite this, for almost thirty years, the LDAP has held its title as the most efficient solution for the organization of corporate data.
Global password patterns: enterprise security culture analysis
The most frequently-used password globally is “123456”. However, analyzing passwords by country can yield some quite fascinating results. We frequently choose weak passwords such as “123456” since they are easy to remember and input. The differences between such passwords can sometimes be found in the language itself. For example, if

8 Things You Should Consider Before Selecting A Corporate Password Manager
A couple of guesses... your mother’s maiden name, your date of birth, your pet’s name. And Bam! It’s stolen.
Password theft has become increasingly common.

Why do I need a password manager?
Password managers protect your accounts by encrypting credentials, generating strong passwords, and blocking phishing attacks. They help individuals and businesses streamline password management, minimizing risks from weak or reused passwords. Discover their key features in the full article.
